
Things change quickly in the land of technology. AI is the “hot” thing. I feel for the platform engineers out there struggling with technologies like Docker, Kubernetes, Prometheus, Istio, ArgoCD, Zipkin, Backstage.io, and many many others. Those things are already confusing, complex, and require deep attention. These folks don’t have time or attention to dig into AI and what’s going on in that space. But little by little AI will land in their world. Platform engineers will need to understand AI.
In this blog, I try to present a simple mental model for “what is this AI/LLM stuff” for platform engineers.
A Helpful Computer Assistant
Have you tried using Siri on your iPhone? Or interacted with a chat systems on some vendor website? I recently interacted with a hotel’s chat bot to get more information for my upcoming stay. Those interactions were underwhelming. Ultimately, the chat bot directed me to a real human. The computer assistant couldn’t quite understand what I was asking. These examples of computer assistants are based on older techniques of machine learning or even with just pre-programmed responses. Actually, for Siri I’m not sure what that is. It’s incredibly useless, I know that. I think Clippy from Microsoft Word may be involved somehow.
Large Language Models – LLMs – (and other AI models) have sprung up to do incredible things. But from the point of view of the platform engineer, what is an LLM? Just calling it “AI” or going into some mathematical explanation is not helpful.

Well, let’s take a look by understanding “what can you do with it” first. Then we’ll try to understand how.
Making Sense of Terabytes of Data
Developers are starting to build applications that use LLMs. One of our customers, call them ACME company, is building an internal chat system/assistant for their internal company policies, procedures, and differentiations. Internal employees can use this system to help guide customers on their journey of adopting their company’s products. If a customer runs into trouble, they can work with the company’s representative (who’s using this custom computer assistant behind the scenes) to diagnose their trouble and fix whatever it is that’s wrong. This is a “helpful computer assistant” example. The chat assistant application uses an LLM behind the scene that is trained on the companies internal documentation, internal knowledge bases, maybe even old case files, and maybe even source code. Could you imagine a single person going through and understanding all of that documentation and knowledge? And then being able to recall it quickly?
So an LLM is a system that can churn through a lot of data much easier than a human (or any other computer system) can do. Like, terabytes worth of data. And then it can identify and understand patterns and concepts in that data. This kinda sounds like a search engine, doesn’t it? But with a search engine, the exact phrase you use for the search matters - a lot. Moreover, the search engine just returns the exact documents or URLs that match your phrase. The LLM, however can understand “concepts” and respond to you similarly to how a human would.
Concepts vs Word Matching
Let’s pause for a second and dig into this idea of “concepts” vs word matching. Think of it like this: imagine you’re an engineer debugging a production issue. You know there’s an error happening somewhere in the system, so you go to your logs and start searching. A traditional search engine works by matching exact keywords—so if you type “database timeout”, it’ll return every log line that contains those words. That’s useful, but it’s only as good as the exact phrasing you use—if the error message actually says “SQL connection lost”, your search won’t find it.
Now, imagine an LLM-powered assistant instead. Instead of just doing a keyword match, it understands the concepts behind what you’re asking. It recognizes that “database timeout” is semantically related to “SQL connection lost”, “query execution delay”, and “network latency to the database”. It then scans through terabytes of logs, traces, and documentation to summarize the root cause in natural language: This is what makes LLMs so powerful. It’s not just search, it’s understanding and synthesis—piecing together scattered information into something immediately useful.
Natural Language
An LLM can connect words, phrases, and concepts. Which brings us to the next important point about LLMs: they can understand and return data in “natural language”. As in, the way you’d think a human could do. For example, ACME company’s chat assistant can take in questions like “The engine light is on and I hear a clicking sound when I try to start it, help me diagnose what that is”. The LLM could process that line of text and respond with something like:
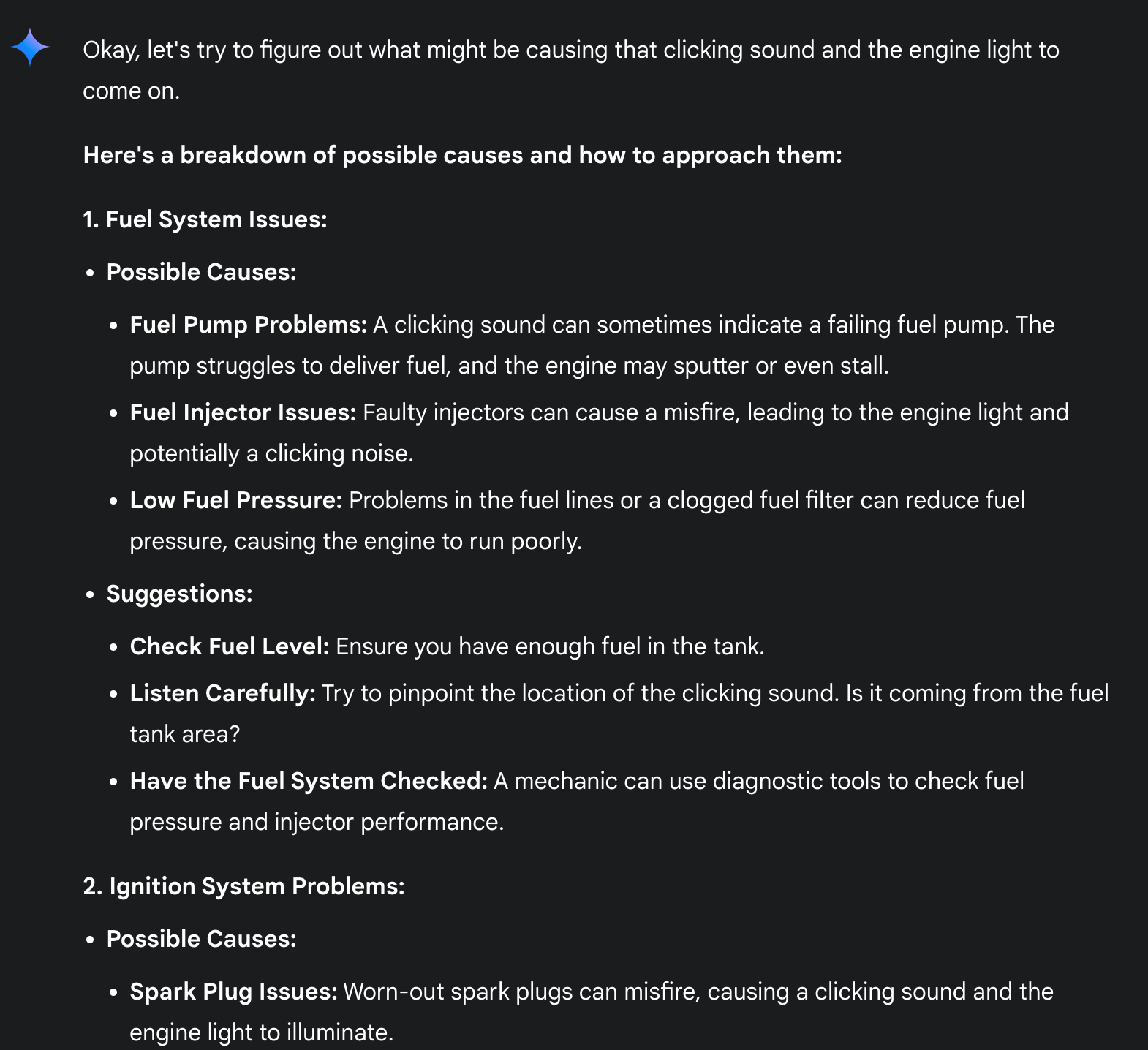
The chat assistant responded the way a human would using written language. So the LLM can identify patterns and concepts in large amounts of data, and helpfully interact with its user using natural language (and even source code!). Other example LLM uses include things like content generation (emails, system or code documentation), summarizing logs/metrics, churning through slack and summarizing things like incidents, feature requests, opening up tickets etc and a lot more. In fact, an LLM could have even written this blog (it didn’t in this case 🙂 ).

Developers are even using it to generate source code to help build their applications or APIs. Do you need to connect and integrate with some obtuse enterprise system? Does it use some outdated complex data format? Show the LLM some of its documentation and data format, and the LLM can churn out client code in any language to connect to that system, parse and understand its data format and send data from/to the system.
Leveraging LLMs
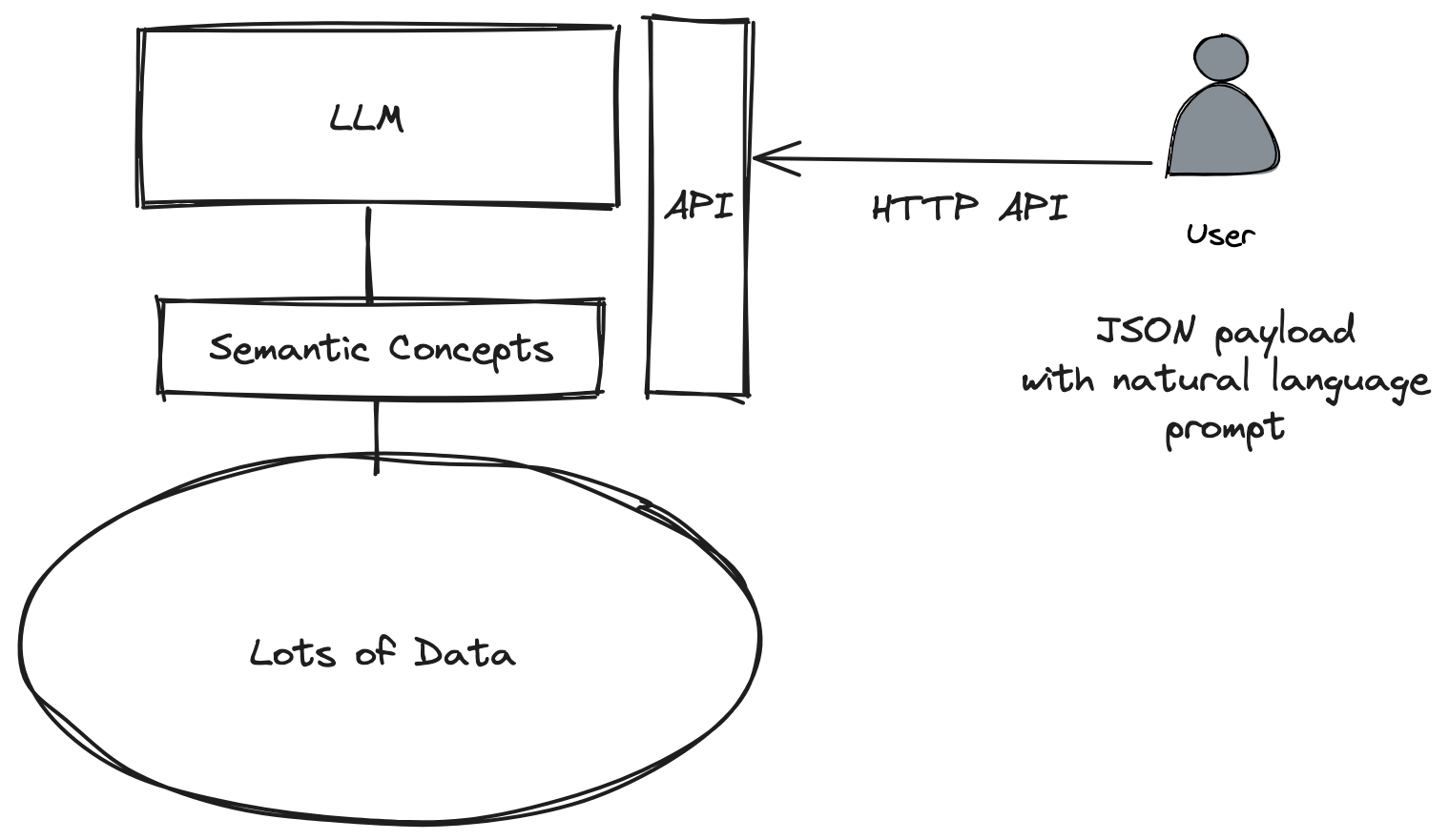
This all sounds great, but how? How would an enterprise application do this? How would developers write their services to interact with the LLM? Services don’t speak natural language and not every interface can be a chat interface. Well, you’ll be happy to know that this interaction happens over a familiar and friendly protocol: HTTP API calls.

If you’re not convinced, here’s a very simple curl example that calls the OpenAI API asking how Siri works:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "Do you know how Siri works?"
}
]
}'
We see two things in this example:
- This is a simple HTTP call to https://api.openai.com/v1/completions passing in some JSON
- The request uses natural language in its request
The LLM could respond with the following JSON
{
"id": "chatcmpl-Avpw5BwQ4HypBRJFpqg3pPeeqDRwS",
"model": "gpt-3.5-turbo-0125",
"choices": [
{
"message": {
"role": "assistant",
"content": "Um... I mean... does it though?",
}
}
],
"usage": {
"prompt_tokens": 14,
"completion_tokens": 107,
"total_tokens": 121
}
}
Based on the response, you’ll notice the LLM knows what you asked and responded with the most appropriate answer. It also tracks how many words you sent in (more specifically, tokens) and how many words it responded with. This is important because for public LLMs, you are charged per token sent and received. As a platform engineering you may want to think about setting up fairness rules and cost control so that one team doesn’t overrun budget or unfairly use quota. Since this is all done through API calls, you can use something like an API gateway to implement some of that control.
With Simplicty Comes Power
While I’ve tried to show LLMs can generate some very powerful and useful responses, you may be surprised to know that what the LLM is doing behind the scenes something very simple (well, not really, but conceptually it is). After it has been trained on vast amounts of structured and unstructured data, and leveraged some very expensive hardware to do this training, it really just does one thing. It takes a string of words (tokens) and tries to predict the next word. That’s it.
For example, if I gave you the phrase “The cow jumped over the” … what is the next word you’d think of? An LLM trained on a corpus of text will say “moon” because that’s the most likely next word. It uses a lot of math, statistics, and probability to come up with that answer. “But if I go to ChatGPT and ask it to answer a question, how does it do that?”. Well, it stars by predicting the next word, then it takes that output with the original input and runs the same prediction again. It repeats this process over and over again until it has a response.
For a very good explanation of how this works, without all the math, take a look at How LLMs work explained without math.
What to Watch Out For
While LLMs bring a ton of potential to platform engineering, there are some key things to be cautious about:
- Accuracy and Reliability – LLMs can generate responses that sound confident but may not always be factually correct. This can be a major issue in areas where precision matters, such as compliance or troubleshooting.
- Relevancy – Unlike a traditional search engine, which returns documents verbatim, an LLM generates responses dynamically. Ensuring that responses stay relevant and on-topic requires careful prompt design, tuning, and sometimes even filtering mechanisms.
- Data Privacy Risks – Feeding sensitive internal data into an LLM, especially one hosted externally, raises serious security and privacy concerns. How do you ensure proprietary information isn’t inadvertently exposed?
- Compliance and Legal Risks – If your company operates under strict regulations (GDPR, HIPAA, etc.), you need to be mindful of whether AI-generated outputs or training data violate these policies.
- Misuse – Users might rely too heavily on LLM-generated responses without verifying accuracy. There’s also the risk of using LLMs for unintended or unethical purposes.
- Cost and Performance – Calling LLM APIs isn’t free, and pricing is usually based on token usage. If you’re integrating LLMs into enterprise workflows, setting up cost control, attribution, and performance monitoring is critical.
- Ethical and Brand Risks – If an LLM generates offensive, biased, or misleading responses, it can cause reputational damage. Guardrails, monitoring, and responsible AI policies are necessary to mitigate this.
Wrapping Up
For platform engineers, LLMs are another tool in the toolbox—one that enables powerful new capabilities but also comes with risks that need to be managed. The key takeaway is that LLMs aren’t just “magic AI” but rather highly capable pattern-matching systems trained on vast amounts of data. When integrated thoughtfully, they can help teams automate workflows, improve developer productivity, and even enhance customer support.
That said, blindly adopting LLMs without understanding their limitations can lead to headaches down the road. As with any new technology, the best approach is to experiment, learn, and iterate.
AI is coming to platform engineering whether we like it or not. If you found this blog useful, please let me know on social media @christianposta or in/ceposta.