
I’ve been writing a lot recently about Agent identity, how crucial it is in Agentic systems for not only security but monitoring, auditing and causality/attribution as well. But we cannot talk about Agent identity without also talking about user identity and delegation. For the user side, we can probably continue to leveage OAuth 2.x (and future enhancements), but what about for Agent identity? The OAuth and OIDC communities are looking to advance the spec and have some very interesting proposals but once question I’ve been getting recently: we already use Istio and rely on SPIFFE for workload identity, can we just use that?
Note, see recent blogs, follow (@christianposta or /in/ceposta) for more:
- Do AI Agents Need Their Own Identity?
- Agent Identity - Impersonation or Delegation?
- Bridging Agent Autonomy and Human Oversight with OIDC CIBA
- AI Agent Delegation - You Can’t Delegate What You Don’t Control
- Will AI Agents Force Us to Finally Do Auth Right?
The TL;DR answer is yes, SPIFFE is a spec designed to be a very flexible Non Human Identity (NHI) that can apply to AI Agents. But not in the way we’ve been using it. Let’s take a look at why that is.
While SPIFFE can technically provide agent identities, current Kubernetes implementations treat all replicas as identical—a fundamental mismatch with agents’ non-deterministic, context-dependent behavior that creates compliance and attribution gaps.
How SPIFFE Works Today (in Kubernetes)
I’m going to take Istio (and service mesh generally) as that is the easiest way to get workload identity based on SPIFFE today. SPIRE, which is a more full implementation of the SPIFFE spec, can handle much more sophisticated attestation flows and CA integrations. But for this example, we’ll look at Istio running in Kubernetes. If you use SPIRE directly, your scenarios may vary.
Workload identity based on SPIFFE today is based on service accounts in Kubernetes. That is, when a Pod comes up, it checks what service account has been assigned to it, and exchanges the service account token for X509 certificates issued by a CA. This X509 certificate has the workload identity encoded into the certificate for example SAN: spiffe://acme-bank.com/ns/default/sa/trading-agent-sa.
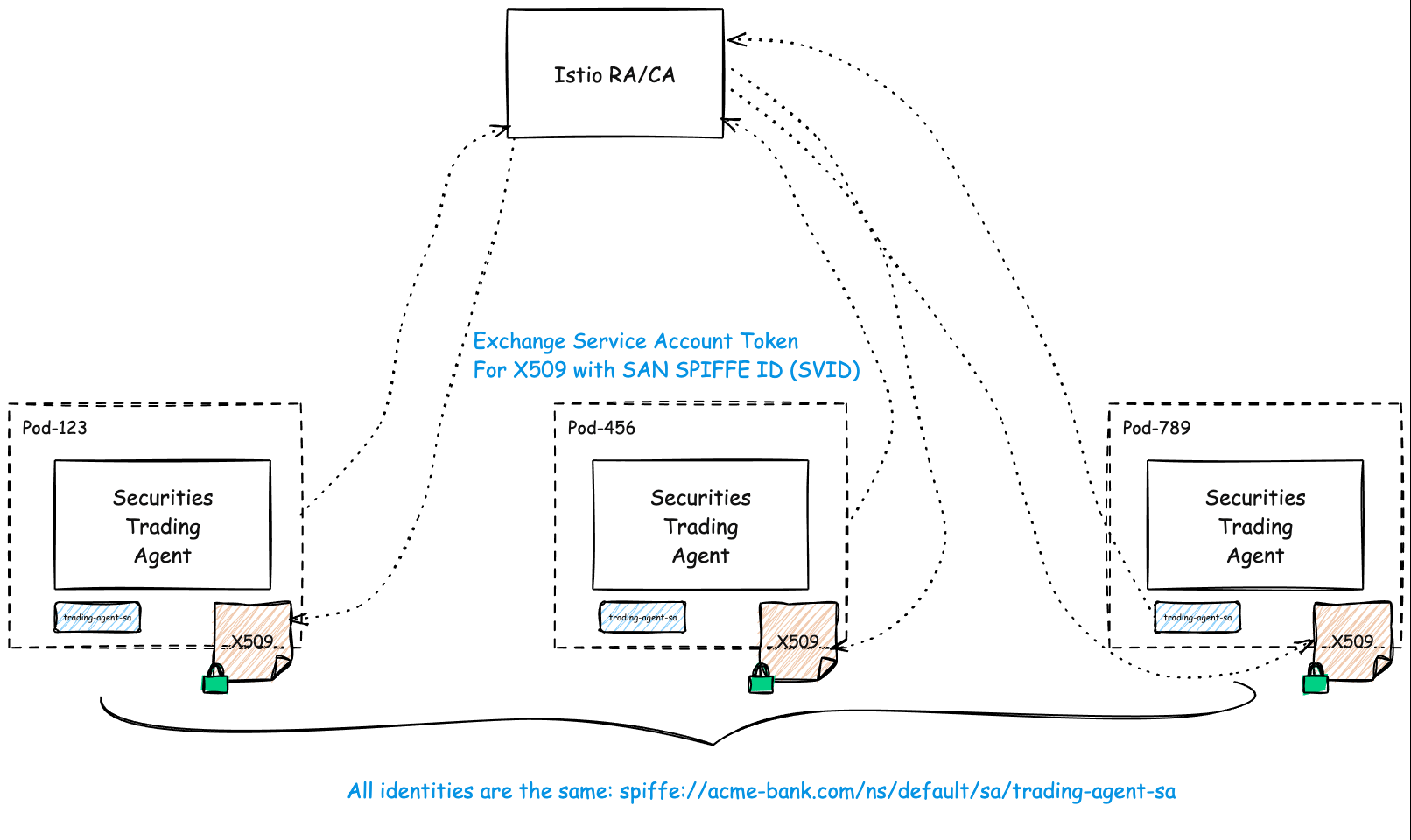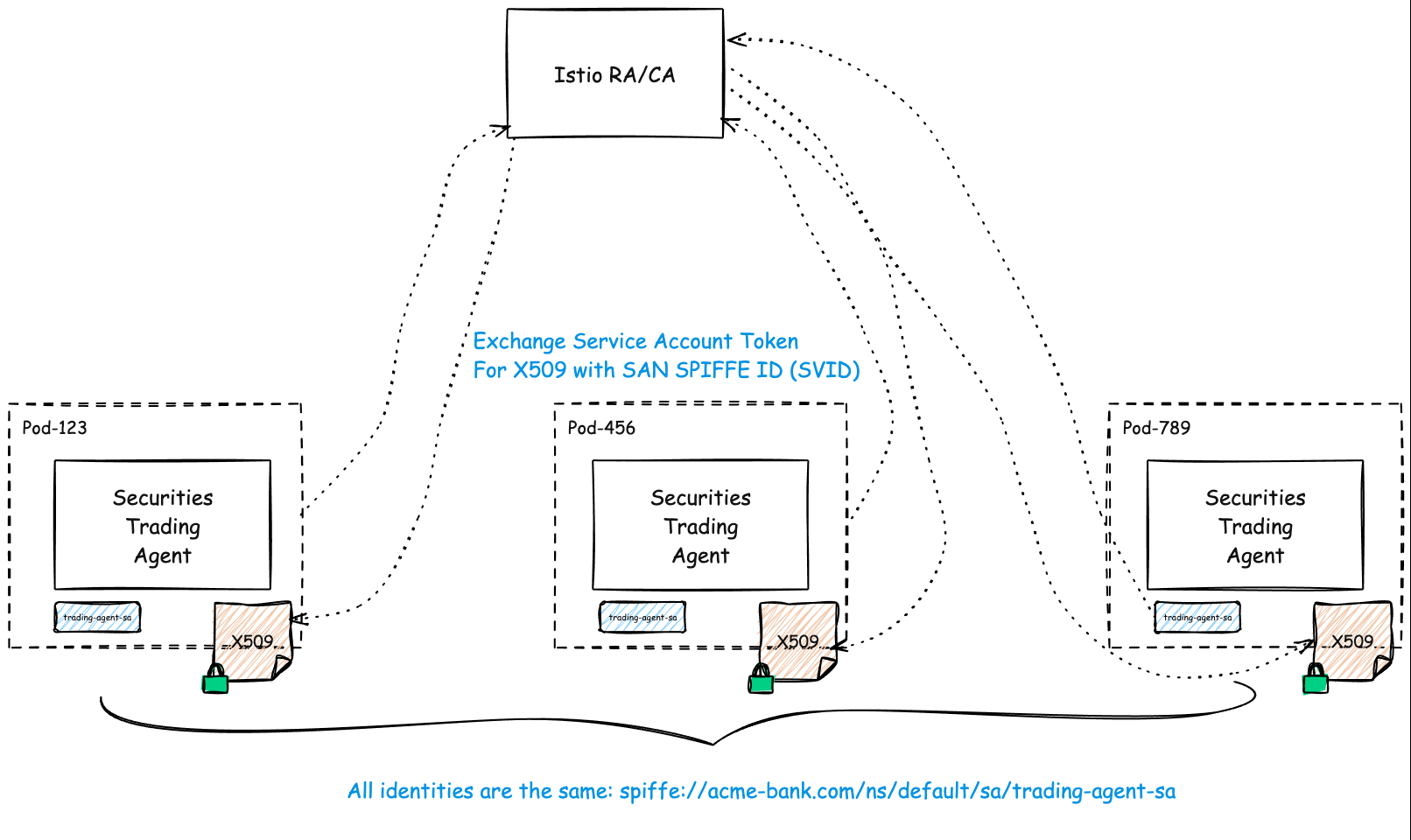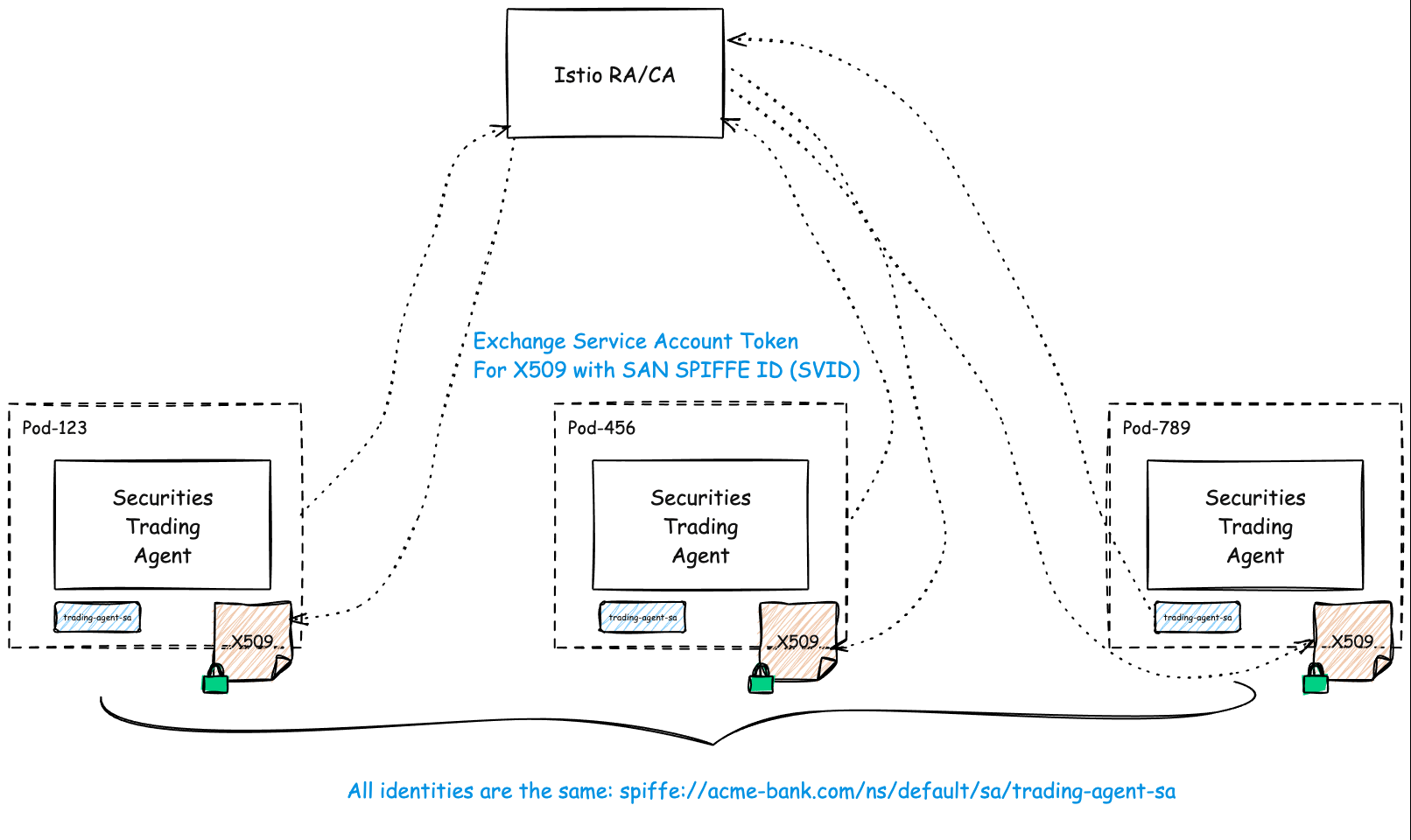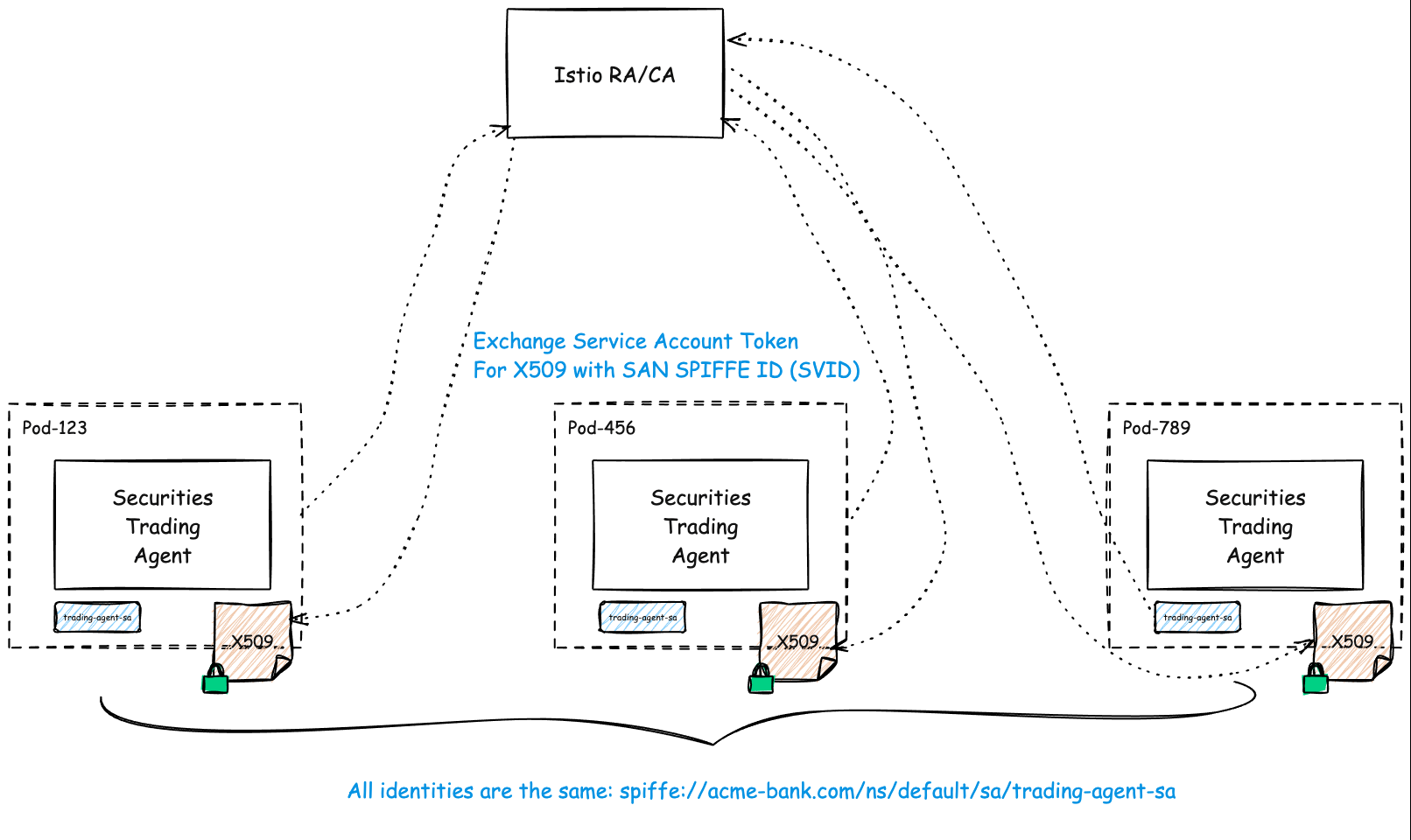
The workload can now use that identity (and certificate) to identify itself and establish authentication (ie, via mTLS). Furthermore, a network administrator can build authorization policies using these strong identities.
Since the SPIFFE identity is anchored in a Kubernetes service account (relying on platform issued identity is a good thing!), that means every Pod with that service account will receive the same identity. For example, a Kubernetes Deployment can configure “replicas” which deploys multiple copies of a Pod, each using the same service account (and thus SPIFFE identity).
# What we have today
apiVersion: apps/v1
kind: Deployment
metadata:
name: trading-agent
spec:
replicas: 4
template:
spec:
serviceAccountName: trading-agent-sa
# Result: spiffe://acme-bank.com/ns/trading/sa/trading-agent-sa
If these workloads are identitcal, ie APIs, web services, stateless applications, etc, then this works great. You can define very strong authorization policies around these identities to achieve strong auditing and compliance controls. But what about if agents are deployed in those workloads?
Agents Change Things
AI Agents are not microservices, APIs, or traditional stateless workloads. They are non-deterministic and their behavior cannot be fully defined by looking at the code. Agents come in many types of flavors: from simple tool/task agents to more complex planner/orchestration/workflow agents. The AI industry seems hell bent on the fact there will be fully autonomous agents so at the moment we have to consider that this will happen. As more enterprises deploy AI agents, we’ll see what the reality truly becomes, but at the moment we have to consider autonomy will include agents making decisions and dynamically discover and call other agents, tools, APIs as desired to achieve an outcome.
The main point here is that agents rely on context (prompt, RAG, tools, etc), historical context (conversation turns, short term / long term memory) and environmental factors (time of day, where its deployed, etc) to make decisions through a probablistc AI model and no two prompts for an agent will produce the same outcome (or set of interactions toward an outcome). So what does this mean? It means that no two replicas of an “agent” are guaranteed to behave the same and from a compliance, security, and auditing standpoint they cannot be considered the same identities.
Let’s consider a simple example:
You’ve built an autonomous AI trading agent, trained on market data and equipped with risk management protocols. Suddenly your agent starts making cryptocurrency purchases at 3 AM. The trades are technically within its permissions, use valid API keys, and follow all the rules you’ve set up in your Kubernetes RBAC policies. Yet something feels fundamentally wrong. When you investigate, you discover that this particular agent instance had been learning from unusual market patterns, building unique context through its interactions, and developing a trading strategy that diverged significantly from its initial programming. Meanwhile, three other “identical” agents running the same code are behaving completely differently, each developing distinct approaches based on their individual experiences and context.
Is this abnormal behavior? Maybe, maybe not, but you (and your auditors) will damn sure want to know Who (which agent), What (what did it do?) Why (why did it make the decisions that it made), and When (3 am !?). If all your auditing and security controls can tell the auditors “well, it came from over here in this general area, but we don’t why”, will that be good enough?
All Agents Need Unique Identities
No matter how big, small, long-lived/short-lived, one replica, many replicas, Agents you have deployed, you will want to know what they’re up to, and prove it to the auditors (and yourself!). You will want unique Agent identities for this.
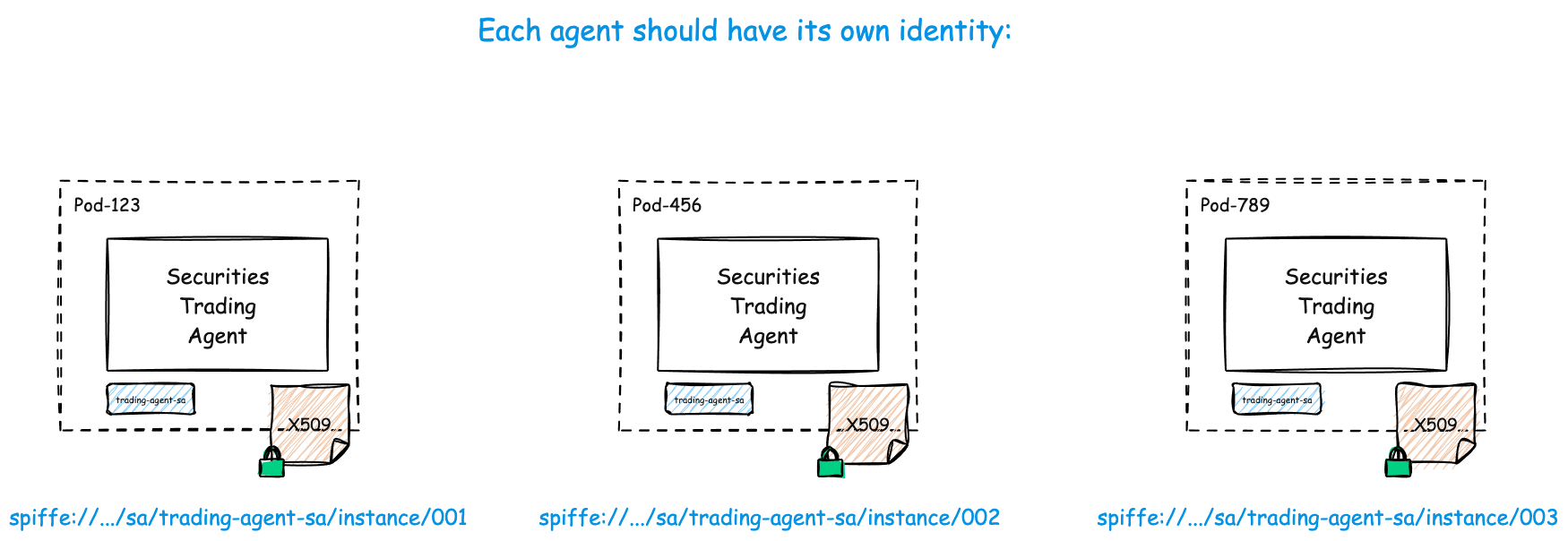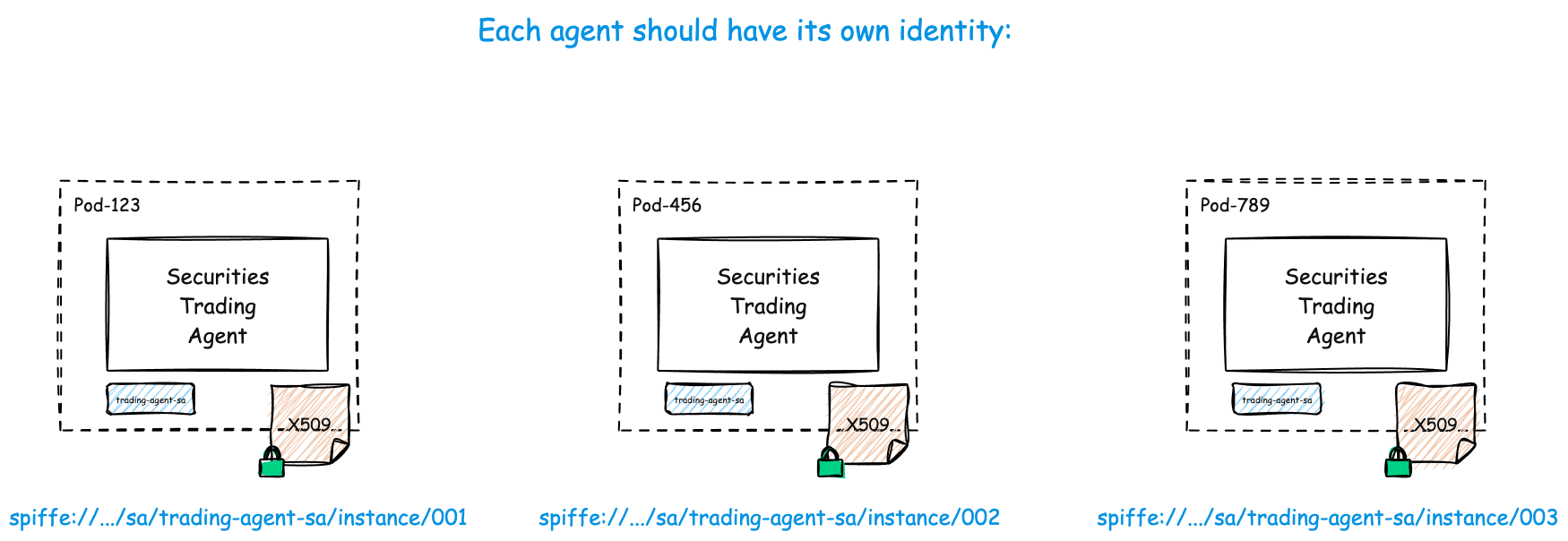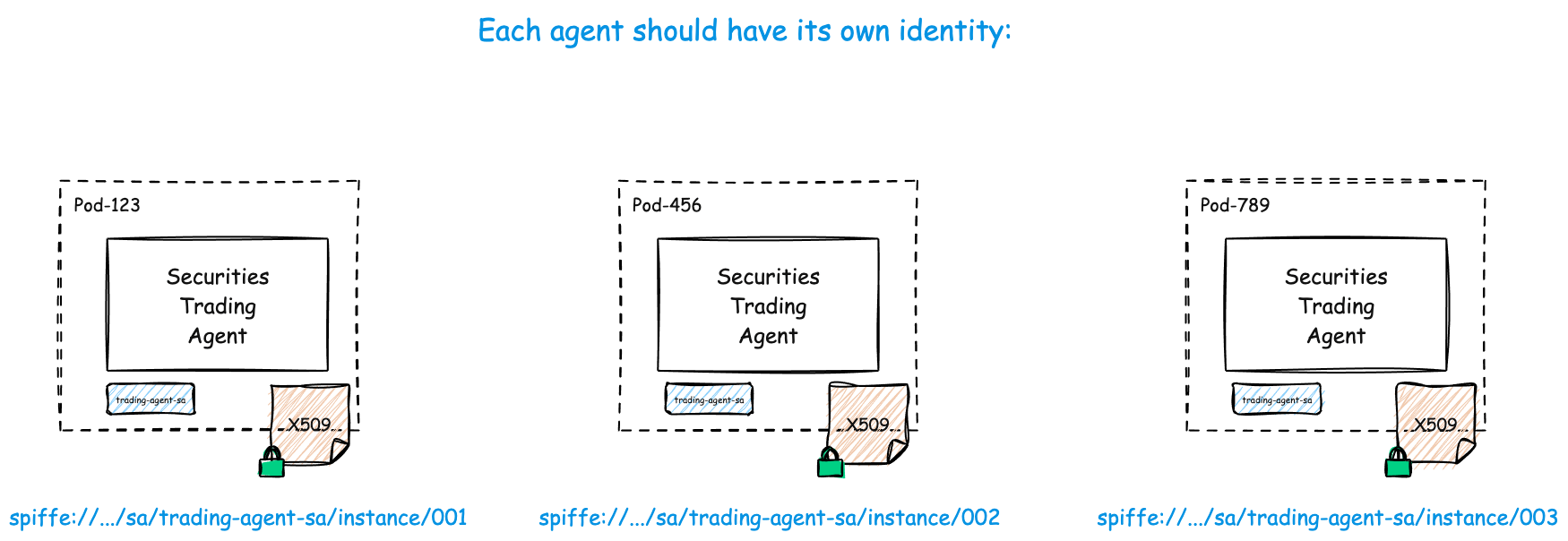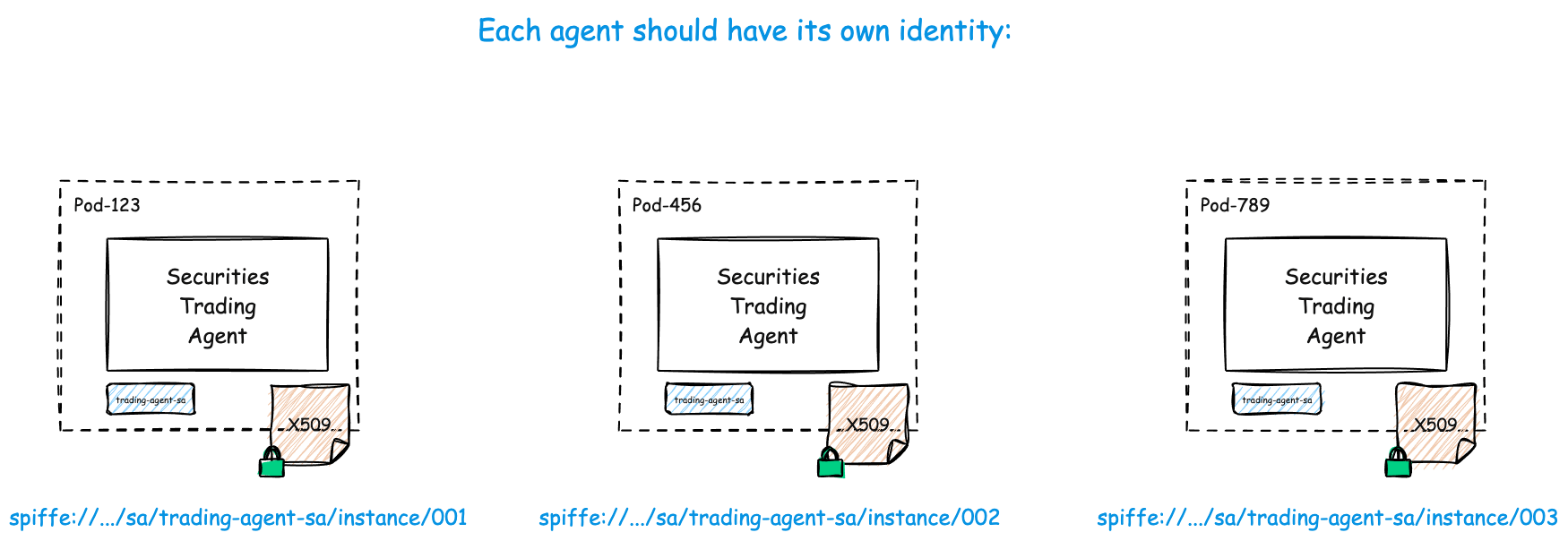
Agent 1: spiffe://acme.com/ns/trading/sa/trading-agent-sa/instance/001
Agent 2: spiffe://acme.com/ns/trading/sa/trading-agent-sa/instance/002
Agent 3: spiffe://acme.com/ns/trading/sa/trading-agent-sa/instance/003
As I said in the beginning, SPIFFE is a very flexible spec for defining identities. Implementations of it (e.g. SPIRE) can be used to support a system like this. A number of questions come up with a model like this, however, the biggest is probably: if identities are more fine-grained, and even potentially generated on the fly, how can you possibly write authorization policies around this? This gets to the heart of how AI agents make a big impact on overall IAM.
We will dig into this more in my next blog. Stay tuned.