
The way LLMs run in Kubernetes is quite a bit different than running web apps or APIs. Recently I was digging into the benefits of the Inference Extensions for the Kubernetes Gateway API and I needed to generate some load for the backend LLMs I deployed (Llama, Qwen, etc). I ended up building an LLM load generation tool because I thought my use case needed some specific controls over how the test was run. In the end, I think about 90% of what I built was fairly generic for an LLM load test tool and I probably could have just tweaked the last 10% with an existing load tool to do what I needed. Nevertheless there were a few important things I learned about generating load against an LLM. Follow me (@christianposta /in/ceposta) for more thoughts on LLM perf as I will reslease some benchmarking results of running LLM inference workloads on GPUs in Kubernetes.
Learning 1: Use Real Prompts
In the past when I’ve done load testing, we’d pick a sample request and send it in a bunch of times. Or if we wanted to vary the requests, we’d generated random text. The point when testing (e.g. API) would be to test request sizes, frequency, routing, failover, latency, throughput, etc. Although the backends would certainly behave differently with different payloads, not usually enough for the types of tests I would run. LLMs are very different.
You don’t want to send in random jumk prompts. LLMs use techniques like speculative decoding rely on predicting token probabilities based on real-world language patterns. Random tokens disrupt these patterns, leading to inflated latency metrics and misleading results. Sending in junk wouldn’t be a realistic test. If you run LLM inferencing in production and collect/log user prompts, you can potentially use those for load testing (assuming there are no data privacy issues with that). Alternative, you can find LLM data sets (even ones used for training) to automate generating test prompts. In my case, when I built my tool, I created a handful of templates and plug-in values into the placeholders as I randomly selected the templates (and values).
Additionally, you should vary the sizes of the prompts. Realistic use prompts are rarely a fixed size and may not reveal any of the underlying mechanics that an LLM uses to process prompts of different sizes (memory handling, etc). In my load testing tool, I specifically vary the input prompts and output max tokens.
Learning 2: Use a Ramp-up Period
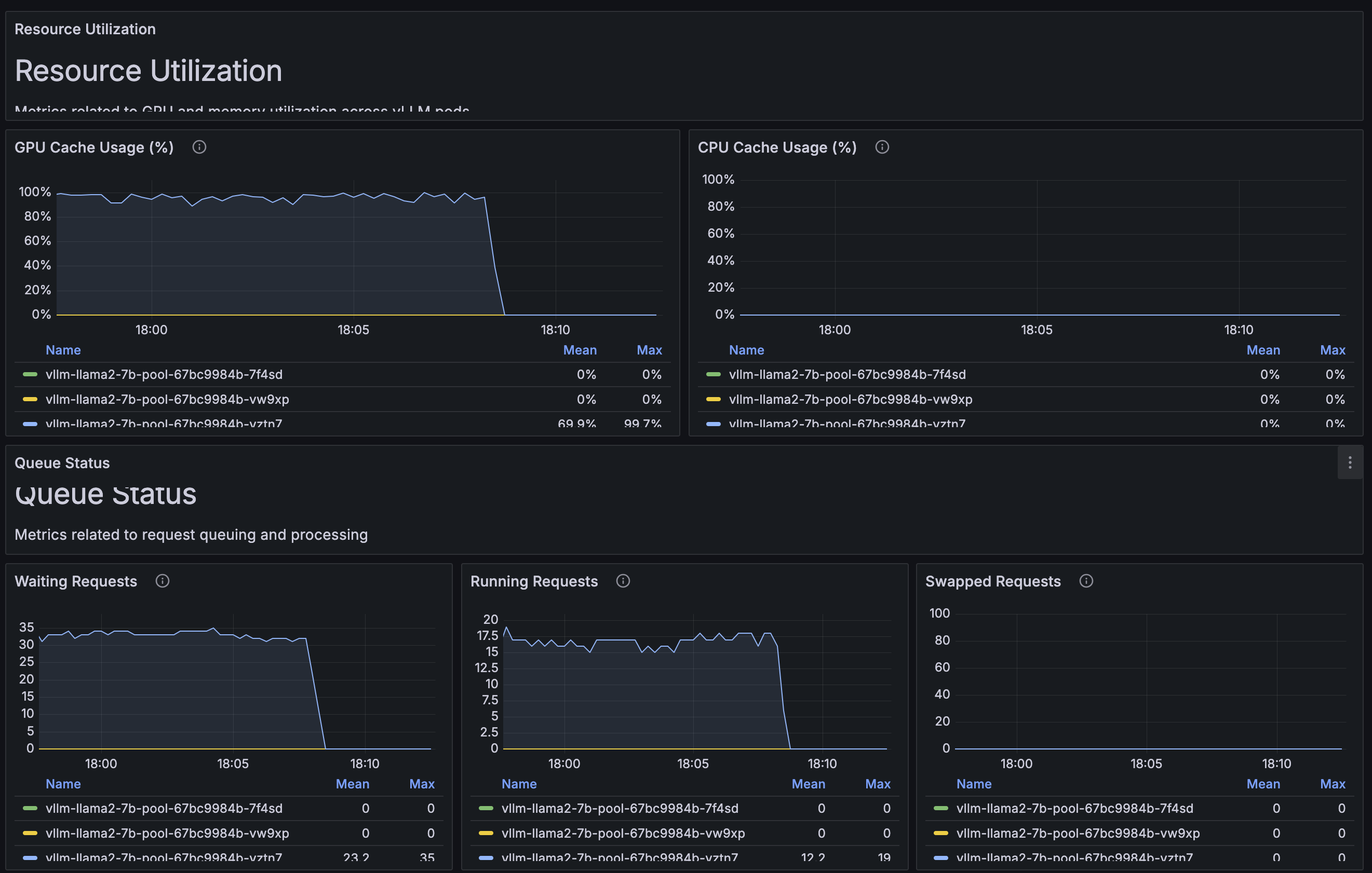
I am sure large-scale systems like Anthropic and OpenAI take massive amounts of load. But for load generation and load testing a certain sized-deployment of LLMs, you should consider that slamming them with massive load up front is not going to produce realistic scenarios. In my load testing, when I forgot about this fact (this applies to APIs, web apps, message brokers, etc also) and saw some amazingly degraded load tests. The LLM gets overwhelemed (wating queues spike, GPU cache consumes 100%, etc) and the LLM spends the rest of the time trying to dig out from under the sudden onslaught. A better approach is to ramp up the traffic gradually. This would likely be more realistic of a scenario and allows you to monitor for interesting inflection points in the performance characteristics of the LLM as load increases. If you find that the load you’ve chosen doesn’t stress the LLMs enough, change the test to send more load, but always consider the ramp up period.
Learning 3: Think about Concurrency
This one may seem obvious, but one point I didn’t realize going into the tests: a single prompt could potentially take up 100% of the GPU. Prompts are very irregular and non-deterministic in how they get processed on the LLM, and consuming the entire GPU is possible. GPUs aren’t the best at multiplexing (unless forced through some hardware / virtualization). In my particular case, I wanted to test what happens to the system under test when the LLMs started to queue requests. For this I wanted to control the number of outbound connections to the LLM (and use a higher number to simulate multiple clients). Some load testing tools by default will start only one connection or a limited connection pool from which to send requests which may or not be enough to stress the system enough. In my case, I created a separate connection per worker and sent requests off that many connections. If I set concurrency to 100, I’d have 100 different/unique connections to the LLMs. From there I could test my load balancing.
Learning 4: Useful metrics to capture
The good folks over at anyscale.com have an amazing blog on LLM performance comparisons in which they indentify LLM performance metrics to capture such as Time To First Token (TTFT), Time Per Output Token (TPOT) and things like end-to-end latency.
In my load testing, I paid close attention to the output metrics given by vLLM and pulled these into Prometheus/Grafana. The metrics that were very interesting to me were the KV/GPU Cache usage, active requests, waiting requests, and average queue time. This gave me a good indication of how loaded the system was going to be. Helpfully enough, the Inference Extensions for Gateway API helps to optimize around these metrics to achieve more intelligent load balancing (which I’ll cover in my next blog).
Good Resources
Here are some great resources if you’re interested in performing LLM load testing or performance testing:
Tools for generating load for LLMs:
- https://github.com/christian-posta/scripted-solo-demos/tree/master/inference-extensions/load
- https://github.com/ray-project/llmperf/tree/main
- https://github.com/AI-Hypercomputer/inference-benchmark
- https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/perf_analyzer/genai-perf/README.html
Load / Perf testing guides
- https://www.linkedin.com/pulse/beginners-guide-performance-testing-large-language-models-benjamin-pg9lc
- https://techcommunity.microsoft.com/blog/azure-ai-services-blog/load-testing-rag-based-generative-ai-applications/4086993
- https://www.patronus.ai/llm-testing