
Enterprises see the power in connecting their data and functionality directly to AI models but most are still treading lightly. The Model Context Protocol (MCP) has quickly emerged as the de facto standard for this kind of AI connectivity, yet it remains very early in its enterprise maturity. What I’m seeing is a split reality: some teams are forging ahead, hacking together proofs of concept to make things work; others are pulling back hard, warning that “MCP is not secure, and we shouldn’t touch it.”
Most MCP servers today are implemented as local stdio servers. That design might make sense for developers and single tenant workstations, but it breaks nearly every enterprise security pattern. It leads to credential sprawl, no centralized governance, zero visibility into how data and access are being used, and ignores established security practices like identity-based access controls. The folks at astrix.security published their State of MCP Security report and found that 88% of MCP servers require credentials and that 53% rely on static, long-lived static secrets like API keys/Personal Access Tokens (PATs).
Enterprises fear what they can’t see or control. They fear the risk of a misstep that could lead to compliance violations, data breaches, or a front-page incident. The current trend of deploying or depending on stdio-based MCP servers for AI agents might work for a POC, but it’s not viable at scale or in production. It moves us backwards and undermines hard-fought progress in security, governance, observability, and dependency management.
In this blog I’m going to propose the following:
- Enterprises should use remote MCP servers by default; NOT stdio
- Leverage existing security, governance, observability approaches; minimize API key / PAT usage
- Leverage a LLM/MCP gateway to gain consistent controls and governance
- Focus on LLM-centric, capability-based design for their remote MCP servers
If you disagree, have alternative view points, or want to share encouragement, I would love to know!! Please share in the comments or social: (My LinkedIn: /in/ceposta)
Current MCP Adoption Patterns
Most organizations I work with have big plans for autonomous agents. However, before even thinking about autonomous agents, most organizations are trying to get their heads around locally running assistant style agents with things like Co-Pilot, Cursor, Claude Desktop, or Goose. These AI agents run locally on a user’s workstation and are configured to connect to enterprise tools or SaaS endpoints like GitHub, Notion, Atlassian, Figma, Snowflake, Databricks, etc.
Under the hood, these agents rely on MCP servers running locally over the stdio transport. The configuration usually lives in plaintext files or environment variables on the user’s machine. When the agent starts up, it spawns the MCP server as a local process and communicates with it through “standard in/out”.
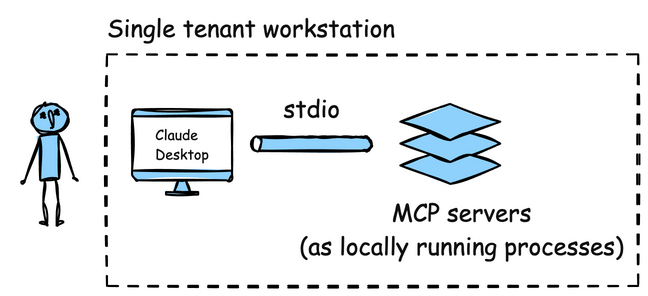
These MCP servers are usually built with Node (npx), Python (uvx) or run in Docker (docker run). For example, a popular MCP server to browse and scrape websites is the Firecrawl MCP server. The Firecrawl MCP server uses npx and is basically a wrapper around the Firecrawl developer APIs but since it’s implemented as MCP, LLMs can be configured to call the exposed MCP tools. But to use these tools, you need to configure a Bearer token / API key. For example, to configure for a local workstation agent:
{
"mcpServers": {
"firecrawl-mcp": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "fake_MncT0pQo7fPjD8yZ5sUaH1bWgVcB"
}
}
}
}
What about for some of the other commonly used MCP servers or agents?
GitHub MCP in VS Code:
{
"mcp": {
"servers": {
"github": {
"command": "docker",
"args": [
"run", "-i", "--rm", "-e", "GITHUB_PERSONAL_ACCESS_TOKEN",
"ghcr.io/github/github-mcp-server"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "fake_MncT0pQo7fPjD8yZ5sUaH1bWgVcB"
}
}
}
}
}
Notion MCP in Cursor:
{
"mcpServers": {
"notionApi": {
"type": "stdio",
"command": "npx",
"args": ["-y", "@notionhq/notion-mcp-server"],
"env": {
"NOTION_TOKEN": "ntn_MncT0pQo7fPjD8yZ5sUaH1bWgVcB"
}
}
}
}
Snowflake MCP in Claude Desktop:
{
"mcpServers": {
"mcp-server-snowflake": {
"command": "uvx",
"args": [
"snowflake-labs-mcp",
"--service-config-file",
"/home/yourusername/path/to/tools_config.yaml",
"--connection-name",
"default"
],
"env": {
"SNOWFLAKE_PAT": "fake_MncT0pQo7fPjD8yZ5sUaH1bWgVcB",
"SNOWFLAKE_ACCOUNT": "your_account_identifier_here",
"SNOWFLAKE_USER": "your_username_here"
}
}
}
}
As you can see, these configurations require some kind of auth credential, either an API key or a Personal Access Token embedded in the configuration file (or environment variables) in plaintext.
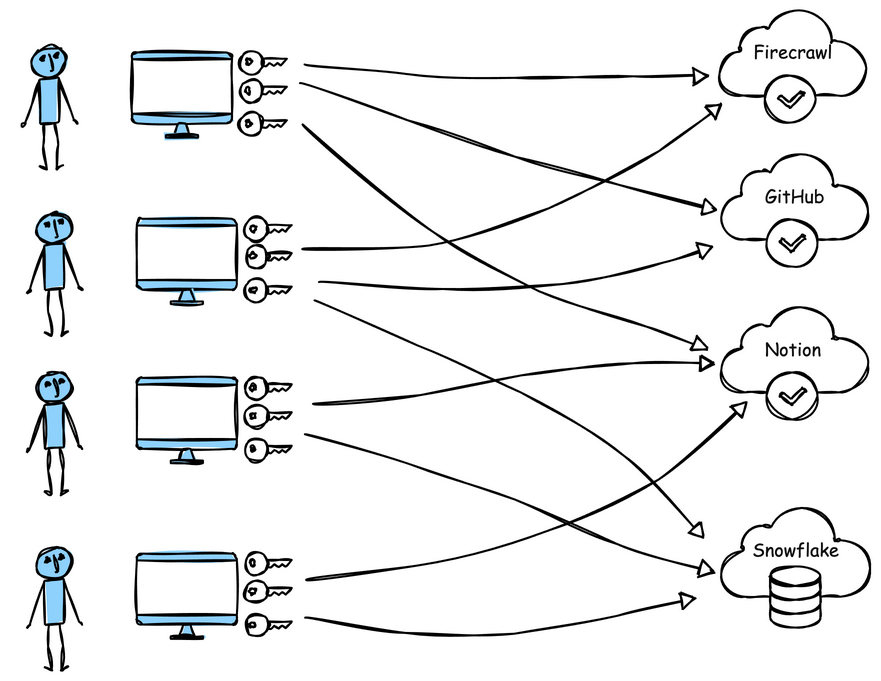
This creates a number of enterprise challenges:
- Credential sprawl: sensitive, long-lived tokens proliferate across laptops
- No identity linkage: credentials aren’t tied to users or devices
- No rotation or revocation: static API keys and PATs remain valid indefinitely
- Bypasses policy: ignores enterprise IAM, SSO, and access controls
- Zero visibility: no monitoring, metrics, or usage logs
- Dependency risk: users install arbitrary MCP servers or images locally
- Supply chain exposure: downloaded packages or Docker images can be compromised
In short: this setup might be acceptable for rapid prototyping, but it should never leave the POC environment. When every workstation becomes its own lousey “API gateway”, security and governance don’t scale and introduces an enormous amount of risk.
MCP Servers Should Be Remote
The MCP specification is fairly flexible when it comes to transport options. Stdio is one option. HTTP Streamable is another option which allows MCP clients/agents to connect over an HTTP transport to an MCP server.
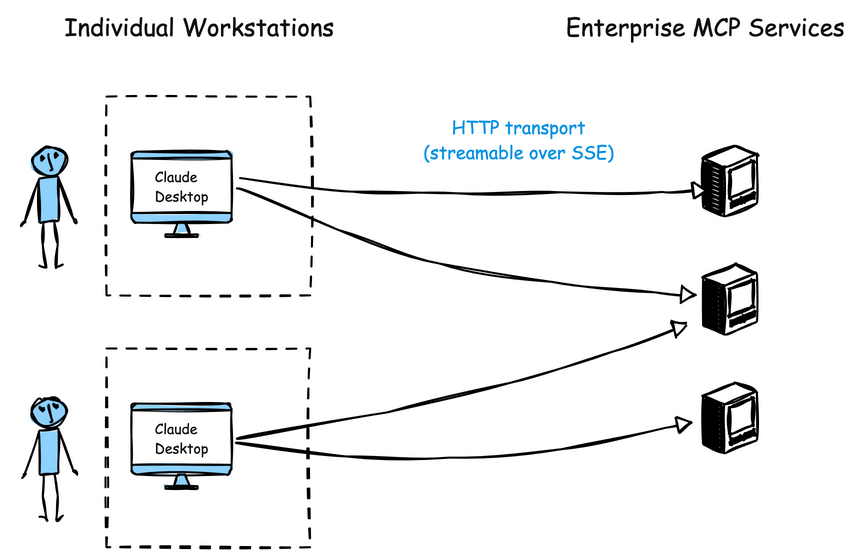
How is this different than the stdio approach? When using the HTTP Streamable transport for MCP clients, there is no locally running/executing MCP server code. The server is fully remote and is accessible only by an HTTP call. This subtle difference changes the dynamics for enterprises quite drastically. If the MCP server is running remotely (within the enterprise), now MCP platform teams can do the following:
- Eliminate long-lived, coarse grained sensitive credentials/sprawl
- Integrate with enterprise SSO/RBAC on HTTP calls
- Centralize observability, logging, alerting
- Monitor usage, detect anomalies, maintain compliance (SOC2, ISO, etc)
- Enforce enterprise policy on usage
- Control what MCP servers are allowed to run (in conjunction with an approved registry)
- Manage upgrade cycles and overall lifecycle
I can already hear you saying:
“But all of the MCP servers ARE stdio!”
That’s true: most MCP servers available today still rely on stdio transport. However, we’re beginning to see a shift. Some SaaS providers are introducing fully hosted, remote MCP services. And a lot of MCP clients are able to support OAuth flows. For example:
{
"servers": {
"github-mcp": {
"type": "http",
"url": "https://api.githubcopilot.com/mcp"
}
}
}
Or Figma MCP:
{
"servers": {
"figma": {
"type": "http",
"url": "https://mcp.figma.com/mcp"
}
}
}
These SaaS managed/hosted MCP servers usually implement the MCP Authorization spec which is OAuth 2.1. So the MCP client will follow the OAuth consent flows. This is better from a “don’t use long-lived API keys” perspective, but still creates governance and observability issues. It’s very important that enterprise policy is implemented, even connecting to these remotely hosted SaaS provided MCP services. So it’s better, but still has issues. But still, I concede that most available MCP servers (or guides for building MCP servers) are focused around the stdio transport.
But that brings us to a very important point.
If you're going to adopt MCP, you must find a way to be secure, governable, observable, and manageable. The current stdio approach to MCP (stdio) is NOT suitable for enterprises.
Here’s my current recommendation for MCP servers in an enterprise
Local stdio MCP servers are only appropriate for simple prototyping OR when the tooling needs to operate locally (ie, filesystems, building local documents, etc).
Implementing Enterprise Remote MCP Services
I think a big part of maturing the Model Context Protocol for enterprise usecases is forcing the issue on remote MCP servers. So what does this mean?
- Clean up the MCP security specs in the community; current MCP auth is NOT suitable for enterprises
- Encourage vendors to offer remote MCP endpoints, not just stdio-based ones.
- Invest in MCP server design — build secure, role-aware, goal-driven tools.
- Build your own internal enterprise MCP service layer
I think we can do all of these things in parallel.
Wait, are you saying we should ignore the existing [stdio] MCP servers and build our own??
In many cases, yes. Given the current gaps in security, governance, and lifecycle management, building remote enterprise MCP services is one of the most effective paths forward. Doing so gives enterprises full control over authentication, observability, tenancy, and upgrade cycles while eliminating risky local configurations.
What does this even look like?
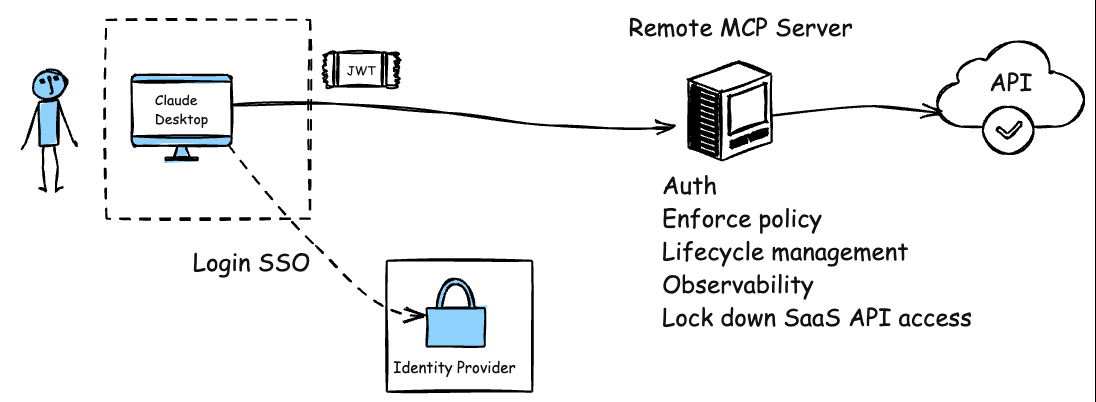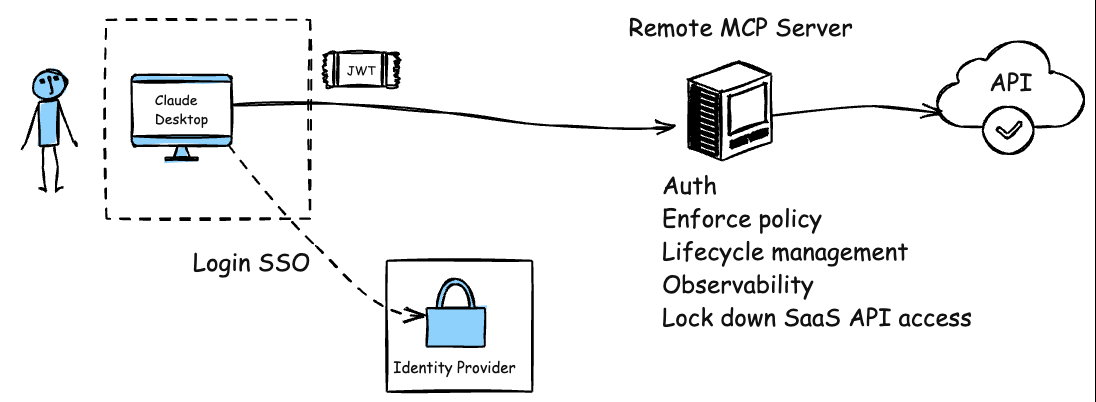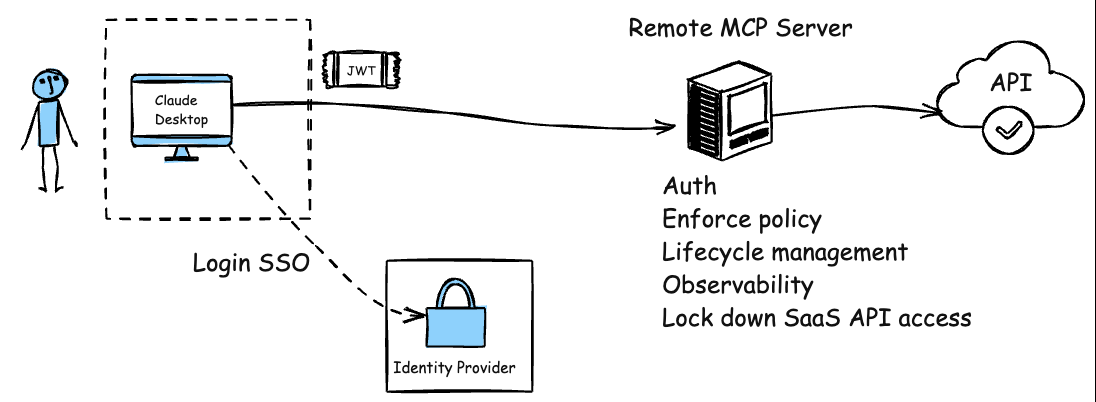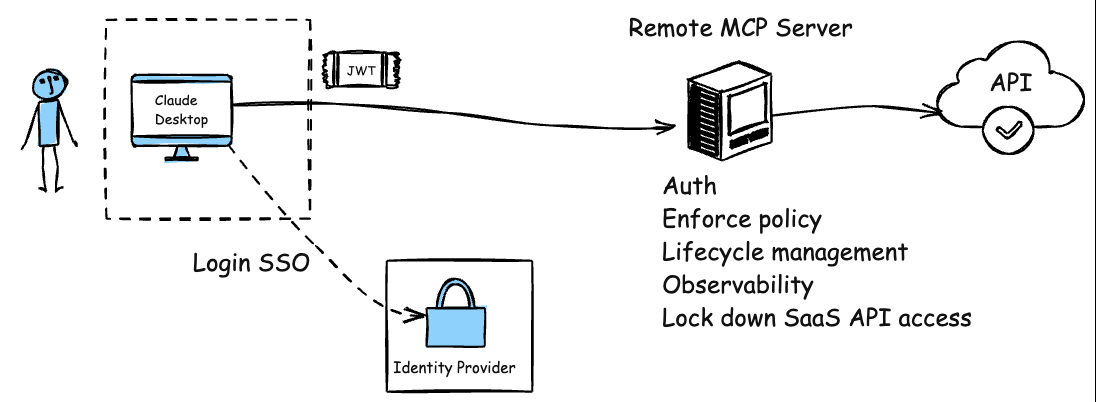
And we can improve this, just like we did with APIs and API gateways. Instead of having each API endpoint/service try to implement its own rate limiting, authentication/authorization, obserability/metrics collection, policy enforcement, et. al, we can leverage a Agent/MCP gateway to consistently handle this for ALL remote MCP servers whether first party, third party, or SaaS:
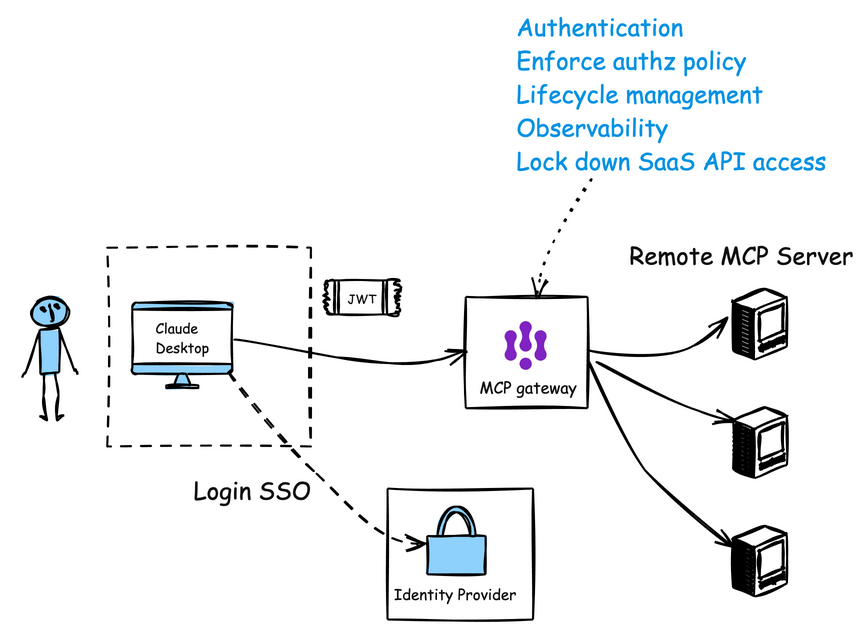
With this model, there’s no need for clients to handle sensitive credentials like API keys or PATs. Instead, the remote MCP server (combined with an MCP gateway) integrates with existing enterprise identity SSO, service accounts, workload identities, etc. It can serve multiple users or agents simultaneously, just like any internal API. This eliminates the need to run extra code on the client side, significantly reducing the surface area for supply chain and credential compromise. With the centralized remote MCP gateway + server approach we gain the following:
- Centrally manage approved MCP services and versions
- Enforce governance and policy on usage and access
- Control lifecycle and upgrades with CI/CD pipelines
- Gain deep observability through unified logging, metrics, and tracing
Further Benefits of Enterprise Remote MCP Services: Intentional LLM-focused MCP Design
Enterprises building their own MCP services brings advantages we’ve already discussed. But there’s another, easily overlooked, win: MCP design for the LLM experience.
We can build on what we’ve leared the last 20 years building and designing APIs. APIs are usually built in layers. Some have called these layers the:
- System API layer: Directly interfaces with underlying systems, databases, and applications. It handles CRUD operations and abstracts system complexities.
- Process API layer: Orchestrates data and processes between System APIs and Experience APIs. It combines data and applies business logic, ensuring smooth data flow.
- Experience API layer: Tailored for specific user experiences, it presents data in a user-friendly manner, optimizing it for different channels such as mobile apps or web interfaces.
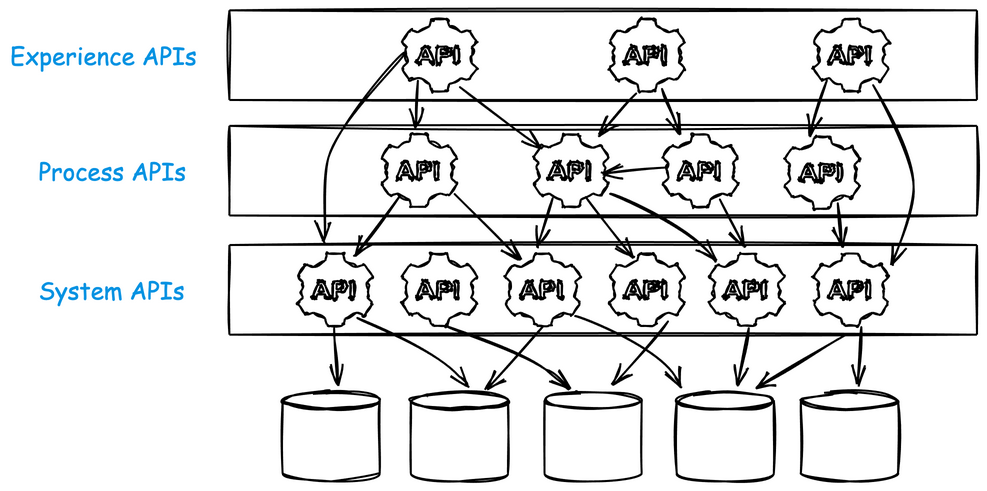
LLM models (and AI agents) care about “capabilities” it can leverage, and how to achieve it’s goals using these capabilities. When an organization builds its own MCP layer, it has the opportunity to design what the LLM-based agentic workflows really need. These look much more like the “Experience API” layer. You should think about building MCP tools “from the top (workflow) down”, not “bottom (system APIs) up”.
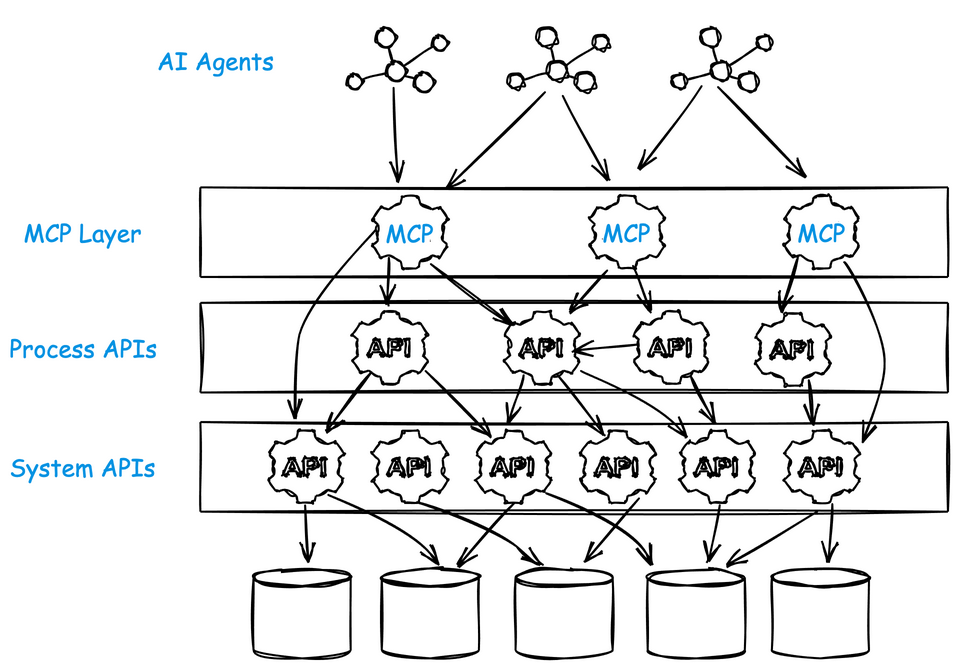
Many of the third-party or off-the-shelf MCP servers in circulation today were built to “get something working fast.” They often do little more than wrap an existing “system APIs” and expose every endpoint as a tool. It’s convenient, but short-sighted. In many ways, it’s counterproductive to how LLMs actually reason about and use tools.
We’re seeing enterprises fall into the same trap internally: taking an existing OpenAPI specification of System APIs and auto-generating MCP tools from it. This technically “works,” but it’s semantically wrong. You end up with dozens or hundreds of narrowly scoped, low-value tools that mirror REST endpoints suitable for machine to machine calls rather than exposing meaningful context to the AI model.
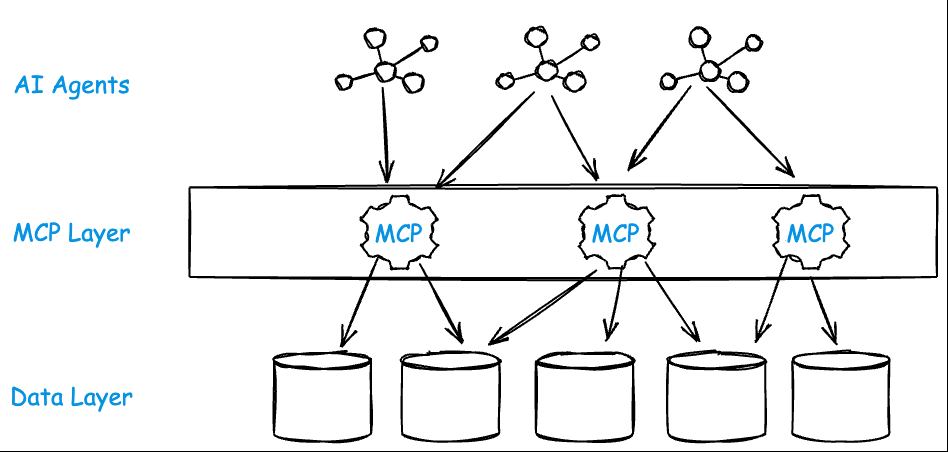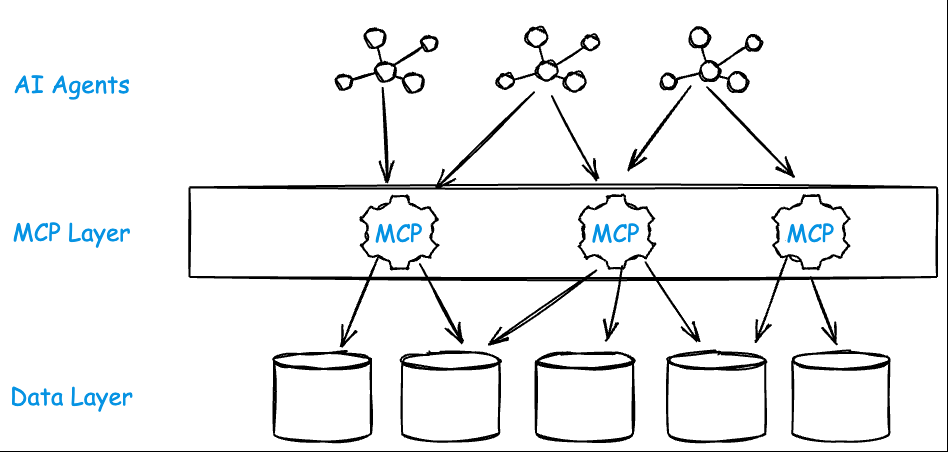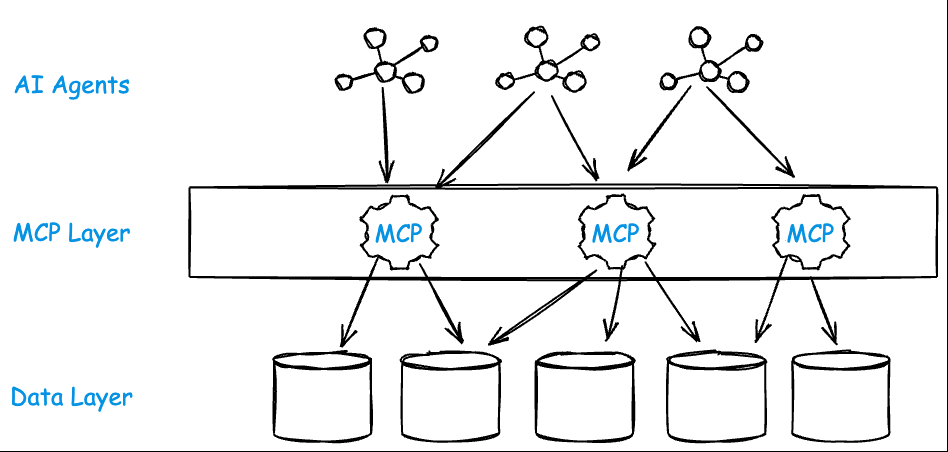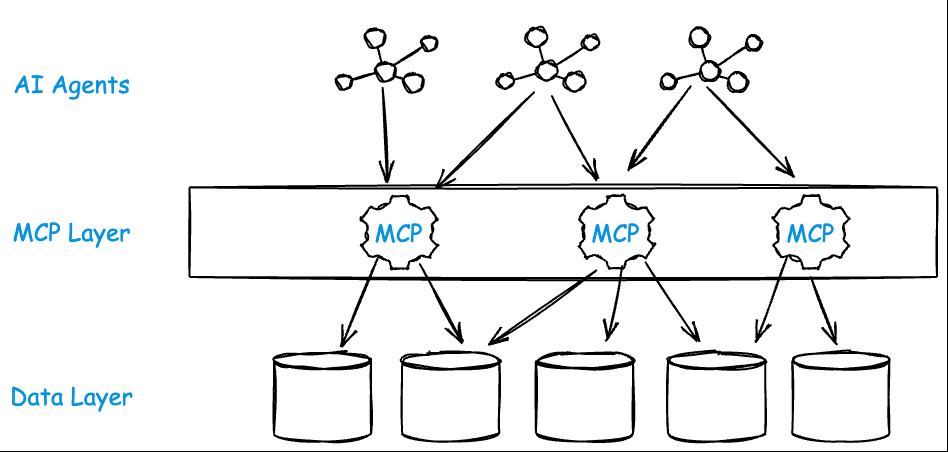
Can an LLM have Cognitive Overload?
Through practice, it’s clear that LLMs struggle once the number of tools grows beyond a small set — 10 to 15 is already a lot. Each tool carries with it descriptive metadata, JSON schemas for inputs and outputs, and contextual hints the model has to hold in its working memory. That all consumes tokens, increases confusion, and amplifies hallucination risk.
The problem gets worse with large, generic MCP servers. For example, the GitHub MCP server exposes over 90 tools by default — covering everything from “create issue” to “list organization members” to “get commit comments.” That’s far beyond what a model can meaningfully reason about or plan with.
The real opportunity for enterprises building MCP services is to invert that approach: design tools around the model’s mental model of the task, not around system API endpoints. Instead of exposing every verb from an API (listTickets, getTicket, createTicket, etc.), group them into coherent, goal-oriented “experience” tools that represent actual tasks your agents perform:
- System APIs: create_ticket, update_ticket, add_comment
-
Experience-oriented MCP: file_support_request
- System APIs: get_build, get_deployments, get_logs
-
Experience-oriented MCP: summarize_recent_deployments
- System APIs: list_docs, search_docs, get_doc
- Experience-oriented MCP: find_relevant_doc_snippets
Each model-oriented tool encapsulates enough of a call sequence, often calling multiple backend APIs behind the scenes, and returns information structured for decision making by the LLM, not raw data dumps. This is where enterprise MCP design shines: teams can bake in domain knowledge, guardrails, and policy enforcement directly at the tool layer.
Drawbacks to Remote MCP Servers
I don’t want my suggestions to come across as a panacea. While they are an appropriate path forward for enterprise, this approach is not without some tradeoffs that must be known up front.
- Remote MCP servers are more complex to implement. They must be deployed into some infrastructure, you must think about high availability, scaling, persistence (if necessary) and most importantly multi-tenancy.
- Guard against confused deputy With a multi-tenant server operating on behalf of users/agents, you need to ensure credential elevation or cross-contamination cannot happen. I’ve previously written at length about MCP server auth patterns, especially for upstream calls.
- Versioning is not straight forward You will need to consider blue/green upgrade paths vs in-place as this will have a big effect on your agents. Blue-green is a well established pattern, but is more complex. It’s worth it though to control upgrade blast radius.
- Discovery of MCP servers is still a problem. You will likely need some kind of registry/catalog
Conclusion
MCP was built to make AI integration easier, but in its current form, it’s making enterprise security, observability, and governance worse. The explosion of local stdio MCP servers has quietly reintroduced the very problems enterprises spent years solving: unmanaged credentials, inconsistent policy, and zero visibility. Each new stdio MCP server running on a developer laptop (or jammed into a deployed agent) is another black box. It pushes API keys, PATs, and secrets into places they were never meant to live. For most organizations, that’s not progress it’s a serious regression.
Move MCP servers out of the workstation and into the enterprise. Use remote, identity-aware MCP servers that enforce SSO, policy, and observability at the platform layer. Treat them like APIs: governed, secured, and monitored. And as we mature this ecosystem, focus on design, not convenience. Great MCP servers aren’t auto-wrapped APIs; they’re intentional, ergonomic interfaces that help models act safely and effectively. They abstract complexity, preserve context, and align with business logic, not endpoint lists.
If you disagree, have alternative view points, or want to share encouragement, I would love to know!! Please share in the comments or social: (My LinkedIn: /in/ceposta)