
Microservices allow us to go faster and reduce our time to value. However, we cannot just naively move fast and break things. We need a way to reduce the risk of making changes and in doing so, make it safer to bring new changes to production. A powerful pattern that helps lower risk of bringing changes into production is to shadow production traffic into a test cluster or a new release of our software and test it for issues before we direct live (aka customer) traffic to it. This allows us to send real-life usecases and obscure useage to our code that our tests in non-production simulations may not catch. I wrote about how Istio Service Mesh has a nice feature for mirroring traffic in my previous post. I actually have a lot to say about Istio and Service Mesh in general, so please feel free to follow along @christianposta to participate and stay up with the latest. Now on to the main course:
The problem with shadowing traffic
When we shadow live production traffic to a test cluster, or in-production dark cluster, we will face a couple of challenges. First, how do we get traffic to this cluster without impacting the critical path of our production service? Do we need to filter out Personal Information from these requests? How do we contain our test cluster to not interfere with live collaborator services? If our service makes changes to data, how do we isolate those changes and not impact production?
These are all real challenges and may be used as reasons to NOT try shadowing traffic. IMHO shadowing represents one of the more important and powerful techniques to doing safe releases, so let’s look at a few patterns for solving some of these problems. The patterns look like this:
- Getting traffic to test clusters without impacting critical path
- Annotating traffic as shadowed traffic
- Compare live service traffic with test cluster after shadowing
- Stubbing out collaborating services for certain test profiles
- Synthetic transactions
- Virtualizing the test-cluster’s database
- Materializing the test-cluster’s database
Let’s dig in.
Getting traffic to test clusters without impacting critical path
This is arguably the most important part. If we cannot reliably shadow the traffic and get it to the test cluster without impacting production traffic flow, then we should just stop. We cannot sacrifice production reliability and availability for our whimsy. Typically we’d use a proxy to shadow this traffic. Envoy Proxy is a proxy that you can use for this. Istio is a service mesh that uses Envoy as the default proxy that enables this capability. See the Istio Mirroring Task for more. So basically, the service mesh (Istio) already sits in between the critical path of our production traffic (to enable resiliency, security, policy enforement, routing control, etc) and can also shadow traffic off to our tests clusters. In fact, this is what we took a deep dive into in my last blog. Importantly, the traffic is mirrored asynchronously and out of band from the production traffic. Any responses are ignored.
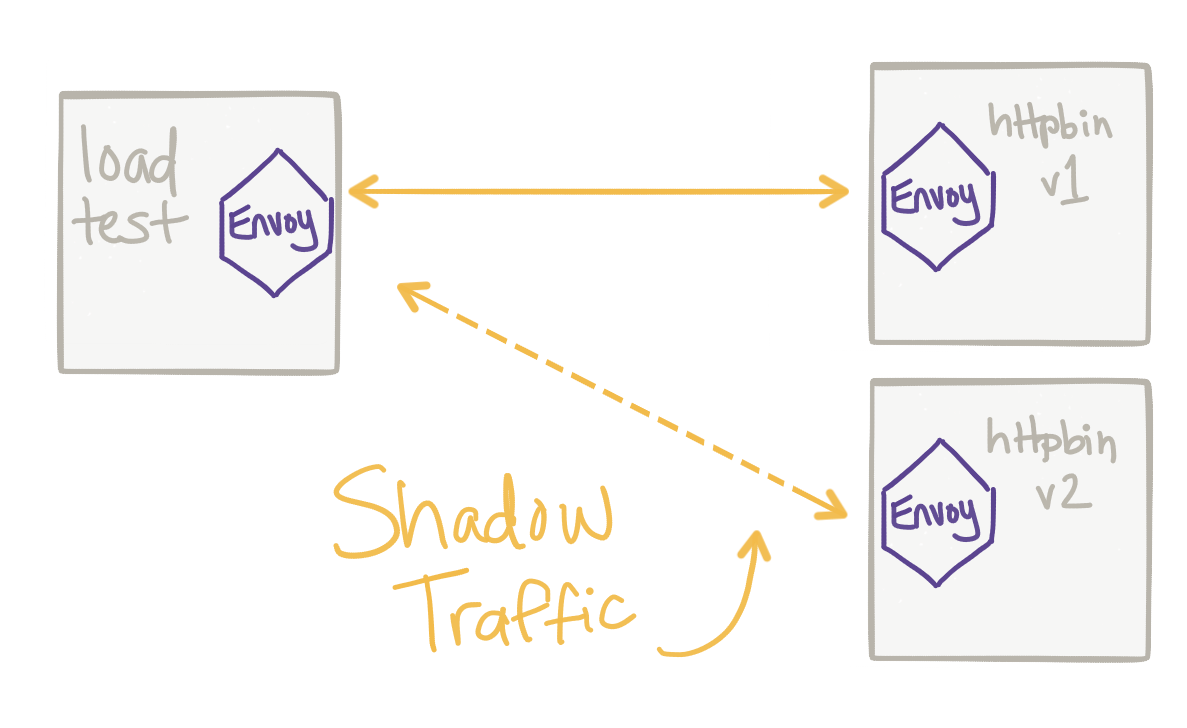
For my readers familiar with the so called “enterprise integration patterns” (thanks Gregor Hophe!) you’ll notice this “mirroring” thing is really a flavor or the wire tap EIP.
Annotating traffic as shadowed traffic
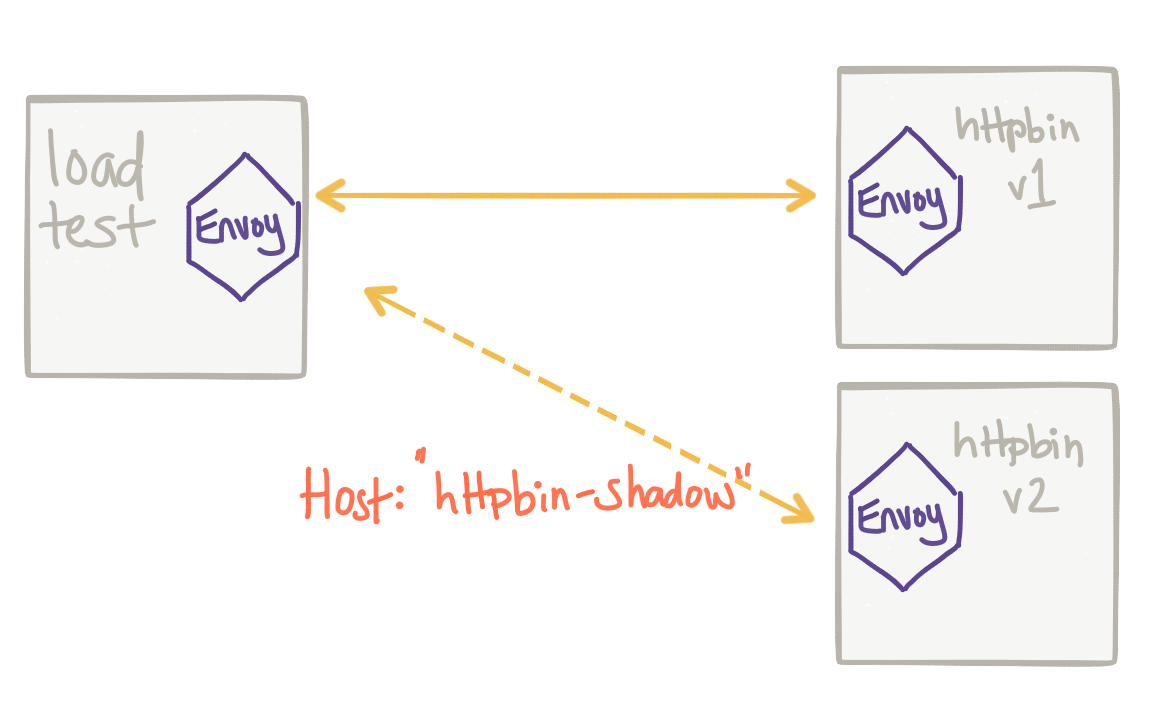
Another important consideration is to identify our traffic that has been mirrored. We need to be able to discern live production traffic and traffic that is for testing purposes. With Istio/Envoy, traffic that is shadowed is automatically annotated with additional context to signify traffic that is mirrored/shadowed. For example, when Istio mirrors traffic, it appends -shadow to the Host or Authority header. For some implementations, this is currently a problem because -shadow will be added to the end of the host so a Host header of foobar:8080 will end up with a header like this: foobar:8080-shadow which is not technically valid HTTP 1.x. With this fix in Envoy, the -shadow postfix gets added to the hostname so foobar:8080 becomes foobar-shadow:8080.
Compare live service traffic with test cluster after shadowing
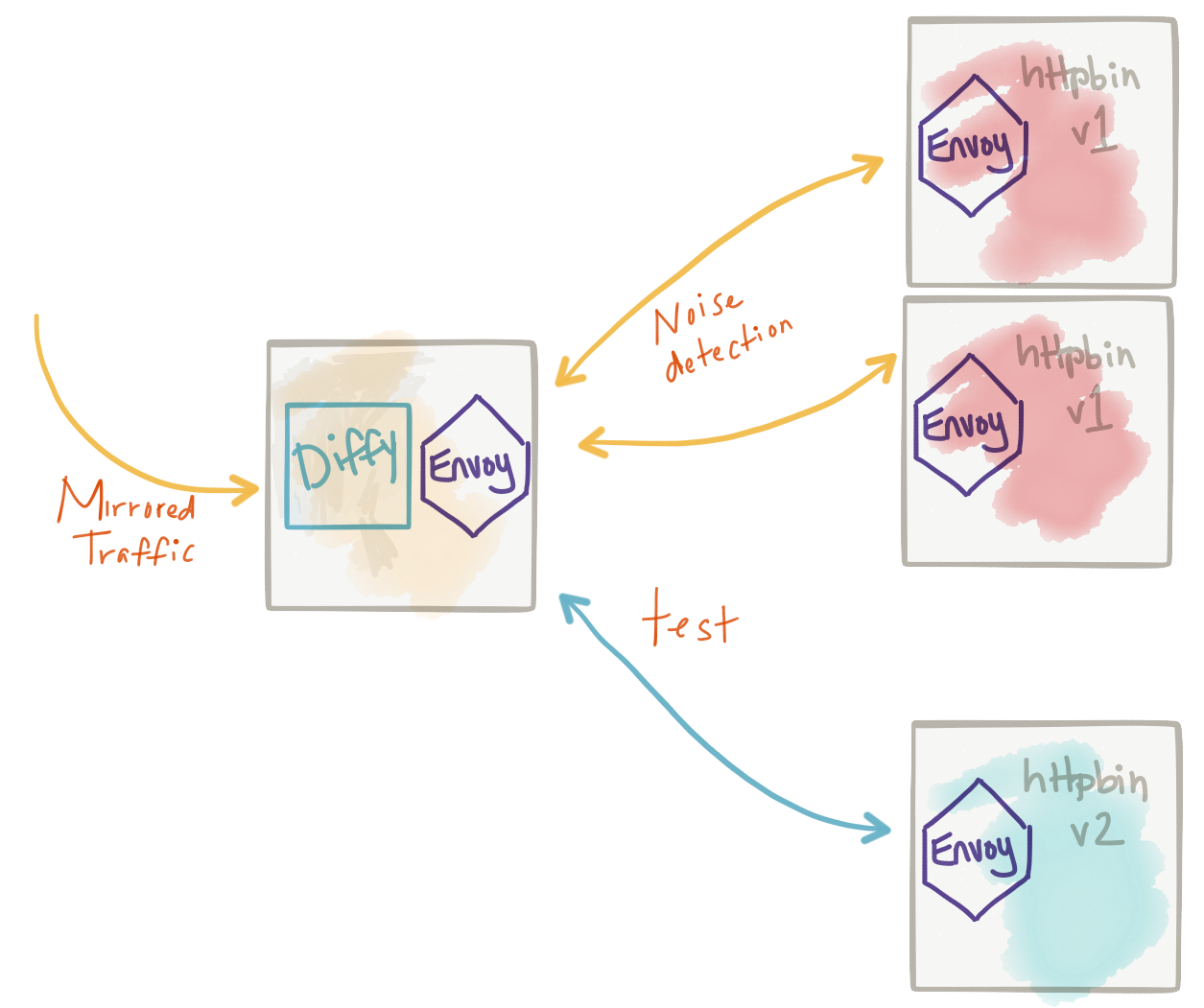
Once we can reliably shadow traffic, we can do some interesting things. We may wish to compare traffic going to a test cluster with expected behavior we see from the live, production cluster. For example, we may wish to compare the results of a request for any deviation in expected results or breakage of API contract for backward and forward compatibility. We can insert a proxy responsible for this type of traffic coordination and one that’s equipped to do interesting comparisons. Twitter Diffy is one of these proxies that’s been sed in production at Twitter and other places for a while to do this. It basically takes mirrored traffic (which we have already, thanks to Istio and Envoy!) and calls the live service and the new service and compares there results. It’s able to detect “noise” in the results and ignore that (ie, timestamp, monotonically increasing counters, etc) by first making calls to two instances of the live service, detecting the noise, then ignoring those parts for the call to the test service.
Diffy also has an awesome web page/dashboard for viewing the results of the calls, their differences, and filtering based on certain characteristics. Lastly, Diffy has a nice admin console for viewing metrics and statistics about the comparisons of the calls.
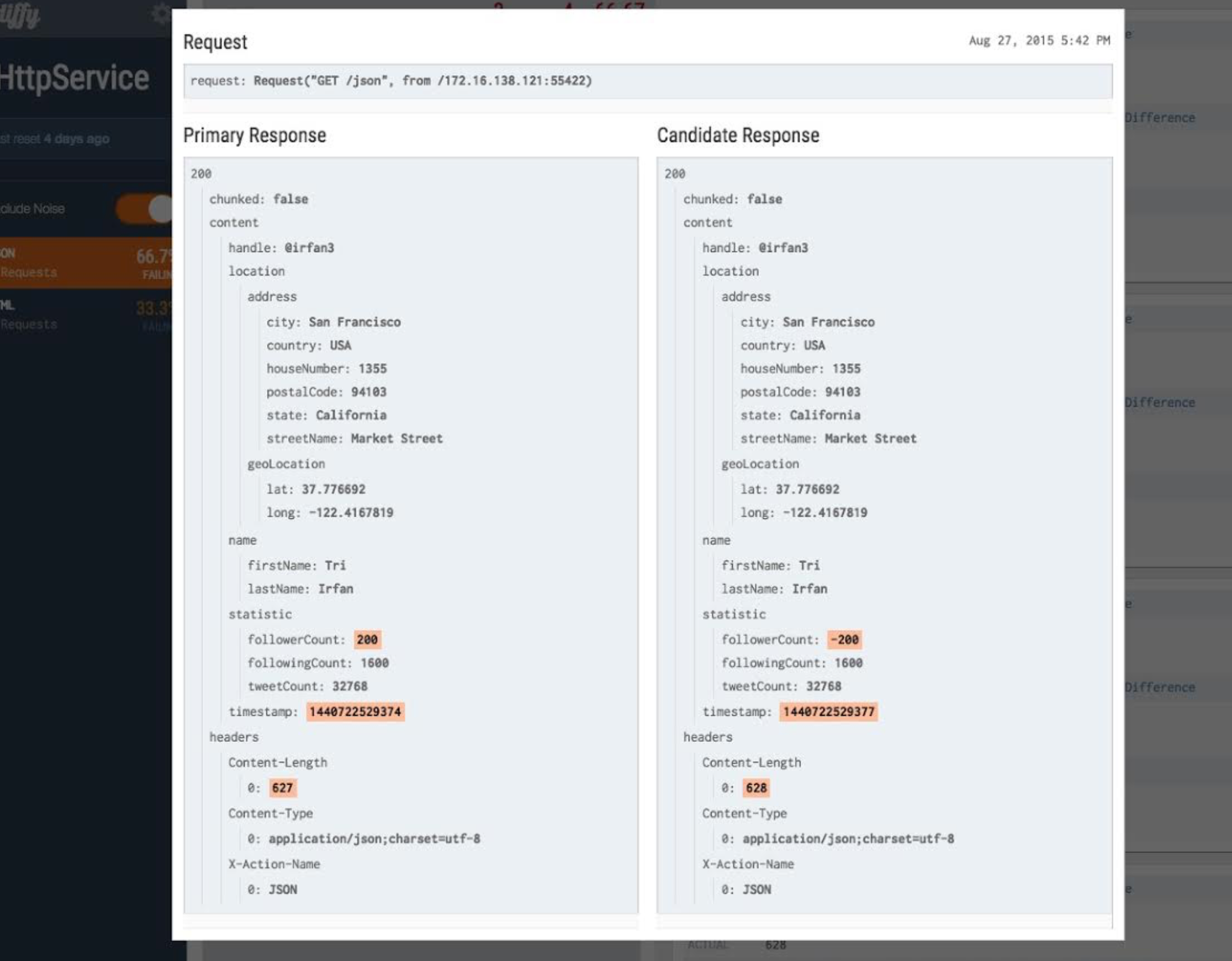
I have a demo of this here with many thanks to Prashant Khanduri, Puneet Khanduri, and Alex Soto. Stay on the look out for a video of this demo as I continue to build it out.
Stubbing out collaborating services for certain test profiles
When we deploy a new version of our service and mirror traffic to the test cluster, we need to be mindful of impact on the rest of the environment. Our service will typically need to collaborate with other services (query for data, update data, etc). This may not be a problem if the collaboration with other services is simply reads or GET requests and those collaborators are able to take on additional load. But if our services mutates data in our collaborators, we need to make sure those calls get directed to test doubles and not the real production traffic. You can create different installation configurations for your deployment which inject these configurations. For example, instead of live.prod.com for a downstream service, we inject test.prod.com. If deploying on Kubernetes, you can use different Config Maps to control this. Another interesting approach is to deploy virtualized test doubles using something like Hoverfly or Microcks. With these service-virtualization tools, you can curate expected request/response pairs and direct traffic that mutates values to these proxies that return expected responses.
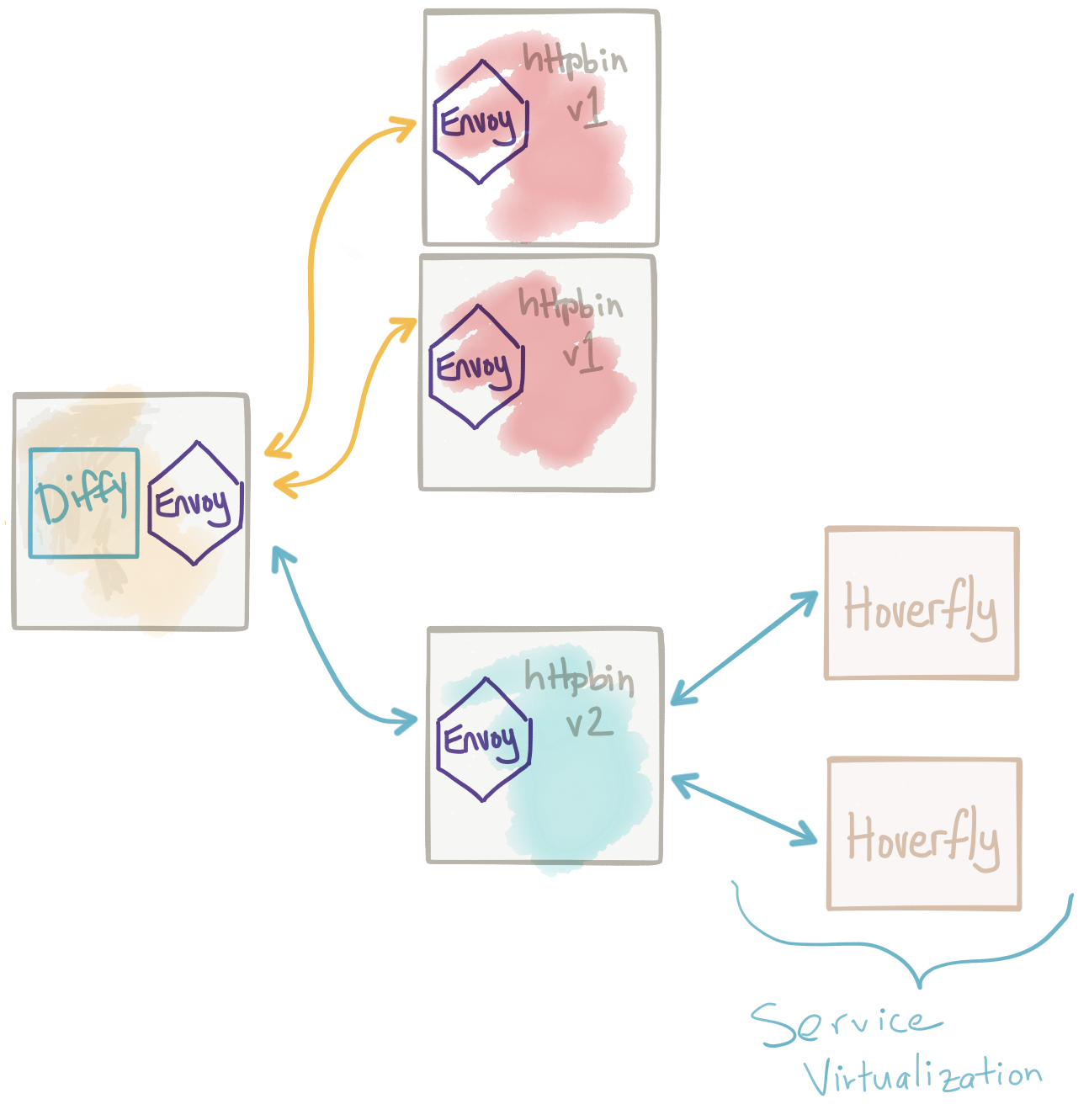
Synthetic transactions
In many cases, the new version of our service will need to mutate data in its local data store. It may make calls out to collaborator services to mutate data, but maybe we cannot (or should not) stub those calls with the previous technique (service virtualization). Another approach is toannotate our calls (like in our previous pattern where we added -shadow) more explicitly to indicate these requests should result in a “synthetic transaction”… i.e., that these are not real transactions and any compensation to undo them should be taken at the end of the request. We can add a header to our request or maybe even make it part of the request body to signal the fact that a certain transaction is “synthetic”. When we do this, we are instructing participating services to process a request as normal, including all data operations, and then to rollback the transaction before commit. Note, this works well with transactional data stores but may not with others. In those cases, if you already have a concept of unit of work, you can attach the synthetic semantics to that. Otherwise, it’d be best to not try synthetic transactions without a way to quarantine and discard changes.
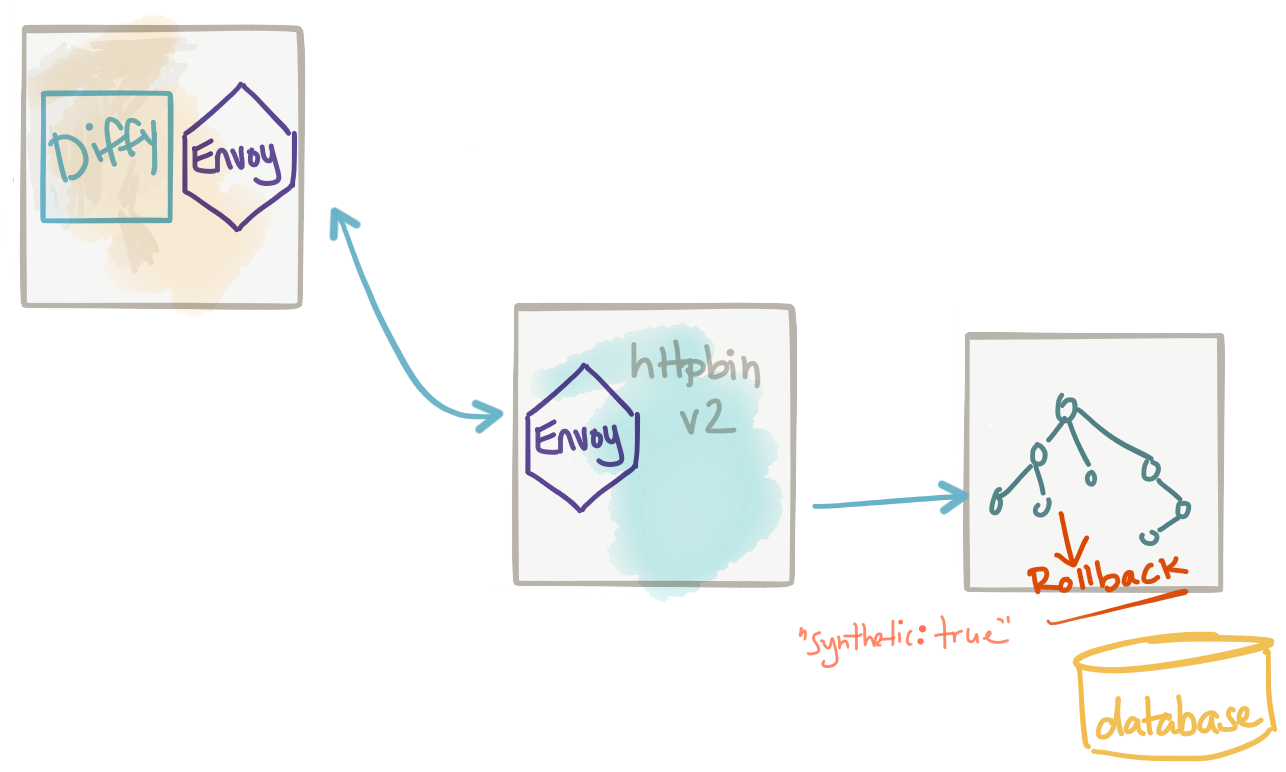
This approach is useful for executing the full path of the request, including data stores, to get a better fidelity of timing, data interference/mismatch issues that you may not catch with a test double approach.
The big drawback to this approach is that it’s implemented by convention and difficult to enforce. It may work with a service you own and have control over, but may not scale to many participating collaborators. You’d hate to try to enforce this convention across all services and have one single service not implement this rollback functionality properly which then messes everything up. Use this pattern in tightly controlled and coordinate deployments.
Virtualizing the test-cluster’s database
We’ve started touching on problems related to dealing with data when testing against mirrored traffic. In general, if your test cluster uses a data store, and the test service updates/inserts/mutates data in some form, you’ll need to isolate those changes. We looked at simply rolling back any changes when signaled with a header or embedded flag, etc. but that’s not always idea.
Another approach to dealing with the data problem when mirroring traffic is to use a fungible data store for your test cluster. You can stand up an empty data store and populate it with test data and run shadowed traffic against that. However, if you’re using something like Diffy (mentioned above), you may get a lot of false positives in response comparisons because the data in the test cluster is using test data while the live services are using production data. A good approach to dealing with this is to virtualize the data layer. We let the test cluster use a data store that presents itself with the same data as the production data store.
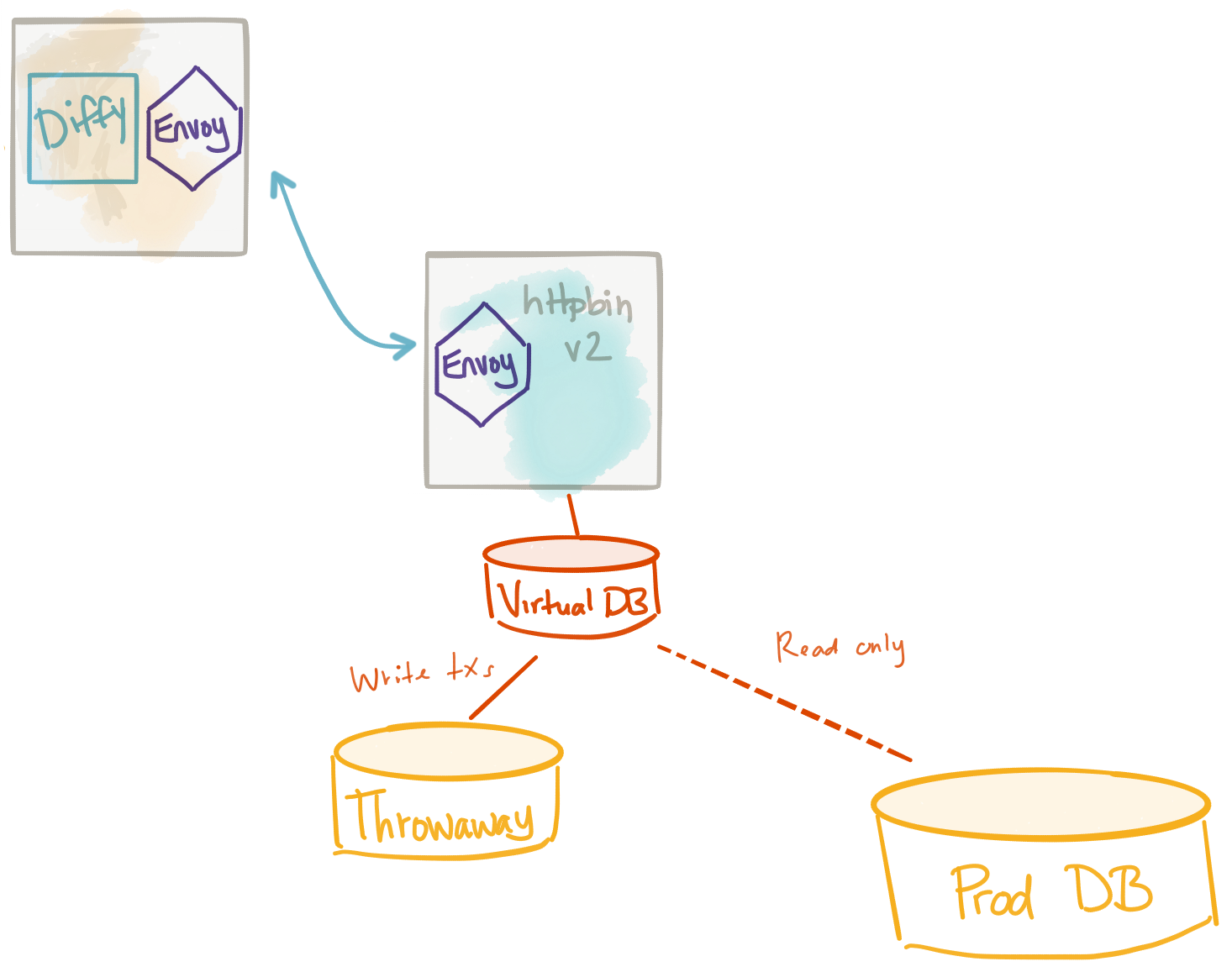
When we do this, we can have a current, consistent view of the production data AND also do writes to the data store without impacting the production data store. We can use tools like JBoss Teiid to do this pretty easily. Teiid has connectors for all types of data store systems including RDBMS, No-SQL systems, flat files, hadoop, salesforce, etc. and can virtualize them for our test cluster. When doing this, any time you make a write, this mutated data can go into a throwaway database but your service has no idea (nor cares). I have a series of blogs that talk a bit about this most noteably this blog post about doing microservice migrations.
Materializing the test-cluster’s database
Lastly, another approach that is an extension of the previous data virtualization technique is to materialize the data store completely. This way, the data store for our test cluster is basically the same as that for the production cluster and is constantly updated via stream processing. The way this works is we capture changes from the production database using (CDC — Change Data Capture) and then send those changes to a new database. Some data stores allow for this as a built-in replication mechanism (think MySQL slave or something) but a lot of times those are read only. You could use a Change Data Capture tool like Debezium to build a simple CDC system to allow your test data stores to have a fully replicated copy of the production data base and use it with impunity. Debezium provides connectors for different data stores and takes the change events from those databases (ie, reads the transaction logs) and streams those changes to Apache Kafka. From there, you can use any stream processing tool to materialize these streams into your test database. FWIW, Teiid mentioned above will have this functionality out of the box soon.
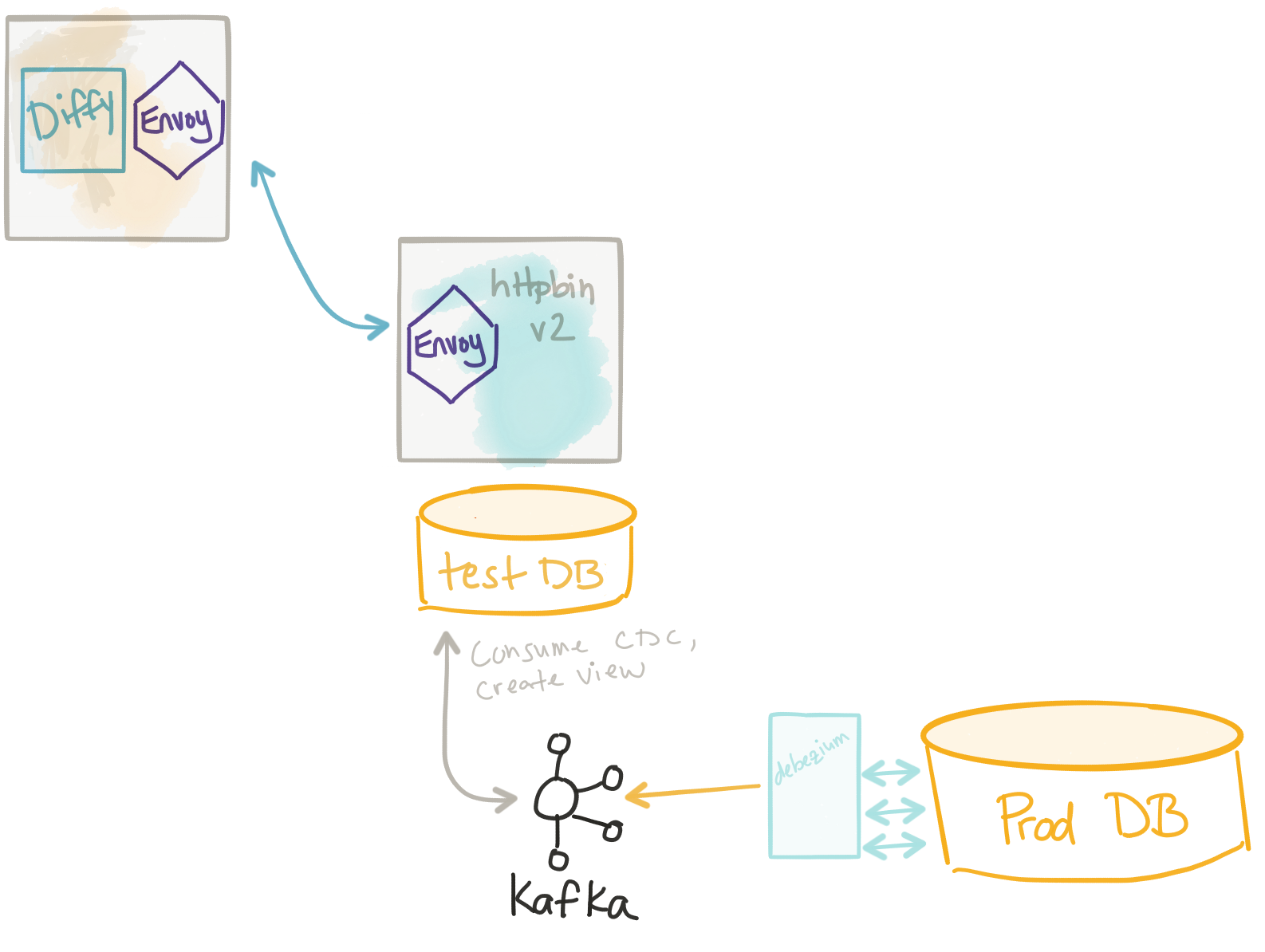
Additionally, if you already have a data streaming pipeline, use an event driven architecture, or use some kind of event-sourced data mechanism, then this “materialized” test database becomes a much better option.
Summary
In practice, mirroring production traffic to our test cluster (whether that cluster exists in production or in non-production environments) is a very powerful way to reduce the risk of new deployments. Big webops companies like Twitter and Amazon have been doing this for years. There are some challenges that come along with this approach, but there exist decent solutions as discussed in the patterns above. If you think I’ve missed something, or feel there’s a nasty problem I’ve not touched on, PLEASE reach out to me and I’ll happily discuss with you and add it to an update of this blog. Thanks!