
I’ve recently started giving a talk about the evolution of integration and the adoption of service mesh, specifically Istio. I’ve been excited about Istio ever since I first heard about it back in January 2017; in fact I’ve been excited about this new wave of technology helping to make microservices and cloud-native architectures a possibility for organizations. Maybe you can tell, as I’ve been writing a lot about it (follow along for the latest @christianposta:
- The Hardest Part of Microservices: Calling Your Services
- Microservices Patterns With Envoy Sidecar Proxy: The series
- http://blog.christianposta.com/microservices/application-network-functions-with-esbs-api-management-and-now-service-mesh/
- Comparing Envoy and Istio Circuit Breaking With Netflix OSS Hystrix
- Traffic Shadowing With Istio: Reducing the Risk of Code Release
- Advanced Traffic-shadowing Patterns for Microservices With Istio Service Mesh
- How a Service Mesh Can Help With Microservices Security
Istio builds on some of the goals of containers and Kubernetes: provide valuable distributed-systems patterns as language-agnostic idioms. For example, Kubernetes manages containers across a fleet of machines by doing things like start/stop, health check, scaling/autoscaling, etc regardless of what’s actually running in the containers. Similarly, Istio can solve challenges of reliability, security, policy, and traffic by transparently applying that outside of the application’s container.
With the announcement of Istio 1.0 on July 31st 2018, we’re seeing a large uptick in Istio usage and adoption. One question I have been seeing is “if Istio provides reliability for me, do I have to worry about it in my application?”
The answer is: abso-freakin-lutely :)
I wrote a post almost exactly a year ago that included this distinction, but didn’t make it forcefully enough; this post is my attempt to help rectify that and builds on the talk earlier referenced.
So just to set some context: Istio provides application-networking “reliability” capabilities like
- automatic retry
- retry quota/budget
- connection timeout
- request timeout
- client-side load balancing
- circuit breaking
- bulkheading
These capabilities are essential when dealing with distributed systems. Networks are not reliable and break a lot of the nice safe assumptions/abstractions we have in a monolith. We’re forced to either solve these problems, or suffer unpredictable system-wide outages.
Taking a step back
The larger problem here is actually just getting applications to talk to each other to solve some business functionality. That’s why we write software, ultimately – to deliver some kind of business value. And that software uses constructs from the business’s domain like “Customer”, “Shopping Cart”, “Account” etc. We see from Domain Driven Design that each service may have slightly different understandings of each of those concepts.
These poorly specified concepts, and the larger business constraints (ie, Customer is uniquely identified by name and email, or Customer can have only one type of Checking account, etc), along with unreliable networking and overall unpredictable infrastructure (build your services with the assumption that things can, and will, fail!) make building things correctly very difficult.
End to end correctness and safety
The fact remains, however, that in terms of building correct and safe applications, the responsibility of doing so becomes that of the application (and all those who support it). We can try to build lower-levels of reliability into components of the system for performance or optimizations, but the overall responsibility still remains with the applications. This principle was covered in “End-to-End Arguments in System Design” by Saltzer, Reed and Clark in 1984. Specifically:
The function in question can completely and correctly be implemented only with the knowledge and help of the application standing at the endpoints of the communication system.
Here, “function” is meant to be one of the application requirements like “book a reservation” or “add an item to a shopping cart”. This kind of functionality cannot be generalized to the communication system or its components/infrastructure (the “communication system” here refers to the network, the middleware, and anything providing infrastructure for applications to do their job):
Therefore, providing that questioned function as a feature of the communication system itself is not possible.
However, we can do things to the communication system to make parts of it reliable and generally assist in accomplishing a higher-order application requirement. We do these things to optimize an area so the application doesn’t have to worry about it “as much”, but it’s not something the application can ignore:
Sometimes an incomplete version of the function provided by the communication system may be useful as a performance enhancement
For example, in the Saltzer paper, they used the example of transferring a file from application A to application B:
![]()
What do we need to do (safety) to ensure the file gets delivered, in tact (correctness)? At any point in the diagram, things can fail: 1) the storage mechanism can have failed sectors/transposed bits/corruptionn, so when application A reads the file, it’s reading a faulty file; 2) the application could have a bug reading the file into memory or sending it out; 3) the network could mix up the byte ordering, duplicate parts of the file, etc. There are optimizations we can make, like using a more reliable transport like TCP or a message queue, but TCP doesn’t know the semantics of “delivering a file correctly” so the best we can hope for is at least when we put things on the network they’ll be delivered reliably.
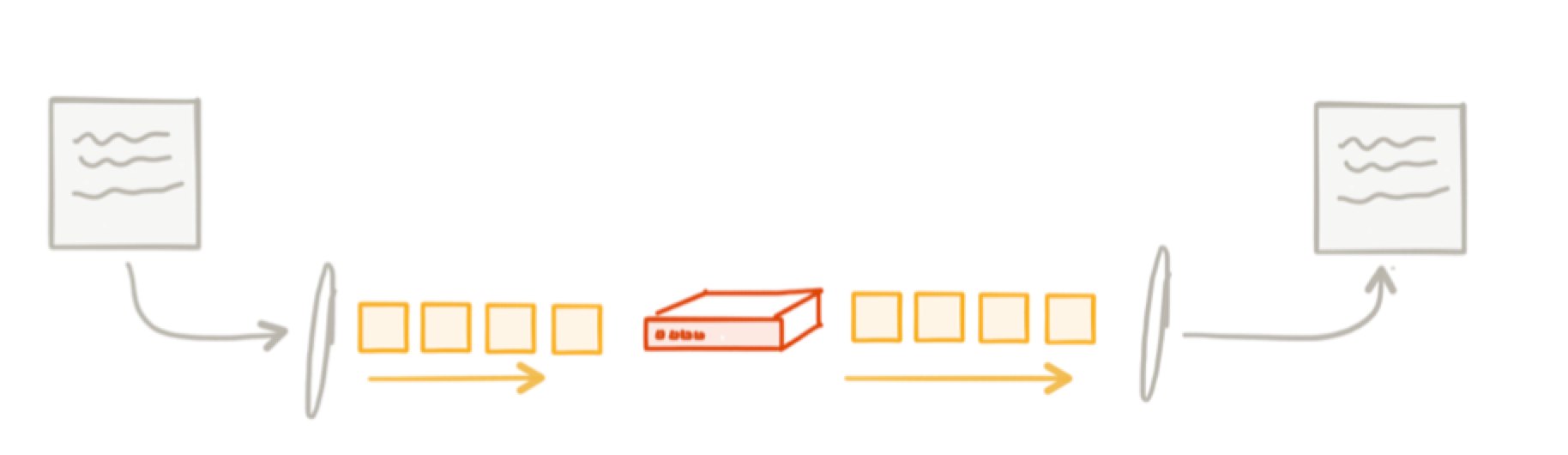
For full end-to-end correctness, we may need to use something like a file checksum that gets stored with the file on it’s initial write and then have B verify the checksum when it receives the file. However we choose to verify that the transfer took place correctly (implementation detail), the responsibility lies with the application to figure out the solution and to get it right, not TCP or a message queue.
What are typical patterns that crop up
In an effort to solve for application correctness and safety in distributed applications, there are patterns that crop up that we can use. Earlier we mentioned some of the reliability patterns that Istio gives us, but those are not the only ones. Generally, there are two classes of patterns that crop up that we can use to assist building applications correctly and safely and both are related. I call those classes “Application Integration” and “Application Networking”. Both are the responsibility of the application. Let’s take a look:
Application Integration
These patterns crop up in the form of:
- Call sequencing, multicasting, and orchestration
- Aggregate responses, transforming message semantics, splitting messages, etc
- Atomicity, consistency issues, saga pattern
- Anti-corruption layers, adapters, boundary transformations
- Message retries, de-duplication/idempotency
- Message re-ordering
- Caching
- Message-level routing
- Retries, timeouts
- Backend/legacy systems integration
Using a simple example of “add an item to a shopping cart”, we can illustrate these concepts:
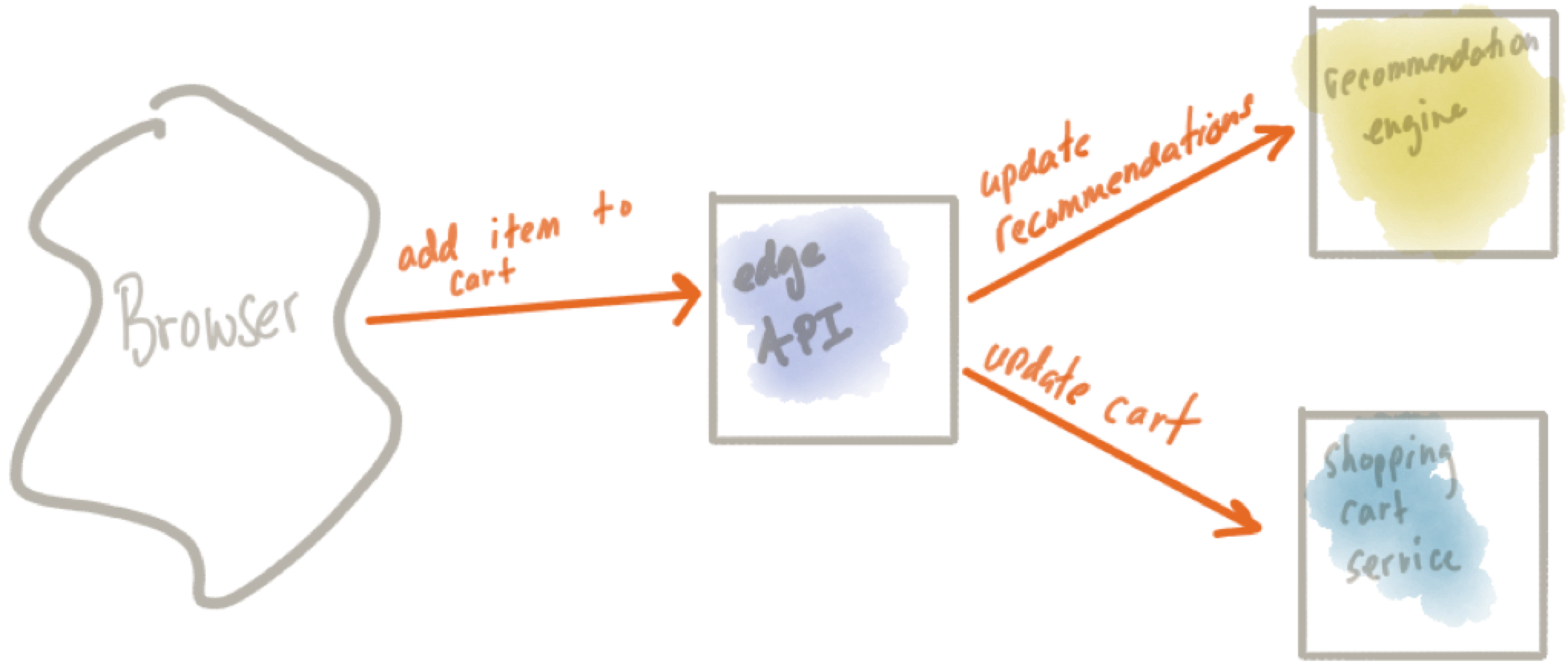
When a user clicks “add to cart” they expect to see the item added to their shopping cart. In the system, this may involve coordinating calls/call sequencing to a recommendation engine (hey, we added this to the cart, wonder if we can compute recommended offers to go along with it), an inventory service, and others before we actually call the service to insert into the shopping cart. We need to be able to handle transforming the message to the different backends, dealing with failures (and rolling back any changes we initiated), and in each one of the services we need to be able to deal with duplicates. What if for some reason the call ends up being slow and the user clicks “add to cart” again? No amount of reliable infrastructure can save us from a user doing this; we need to detect and implement duplication checking/idempotent services in the application.
Application Networking
These patterns come in the form of:
- automatic retry
- retry quota/budget
- connection timeout
- request timeout
- client-side load balancing
- circuit breaking
- bulkheading
But also other complications of dealing with applications communicating over the network:
- Canary rollout
- Traffic routing
- Metrics collection
- Distributed tracing
- Traffic shadowing
- Fault injection
- Health checking
- Security
- Organizational policy
How do we use these patterns?
In the past, we tried to commingle these areas of application responsibility. We would do things like shove everything into centralized infrastructure that was counted on to be basically 100% available (application networking + application integration). We put application concerns into this centralized infrastructure (which was supposed to make us more agile) but then suffered bottlenecks and rigidness when it came to making changes to applications quickly. These dynamics manifested in the way we implemented Enterprise Service Bus:
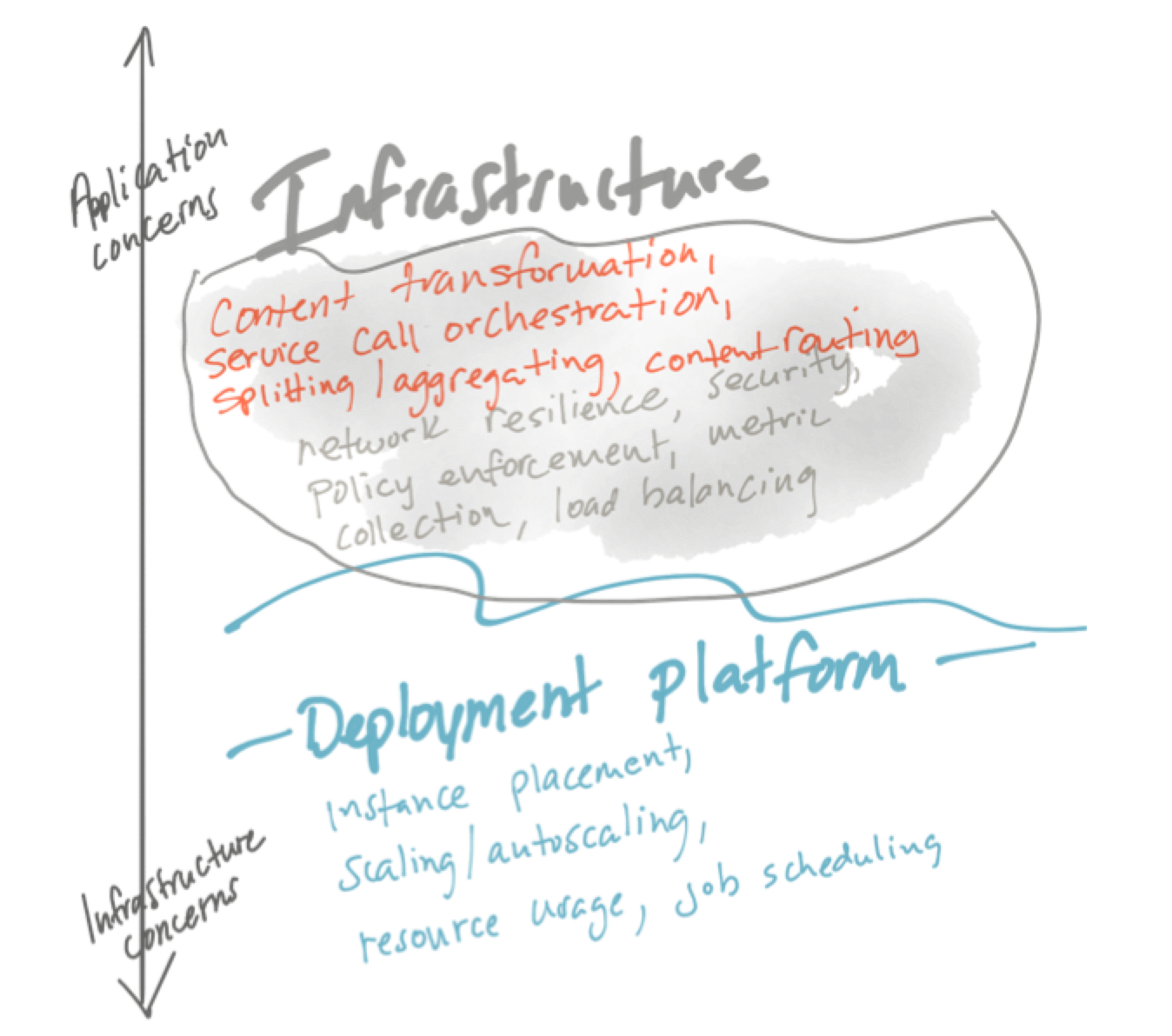
Alternatively, I believe the big clouds (Netflix, Amazon, Twitter, etc) recognized this “application responsibility” aspect to these patterns and just commingled the application networking code into the application. Think things like Netflix OSS where we had different libraries for circuit breaking, client-side load balancing, service discovery, etc.
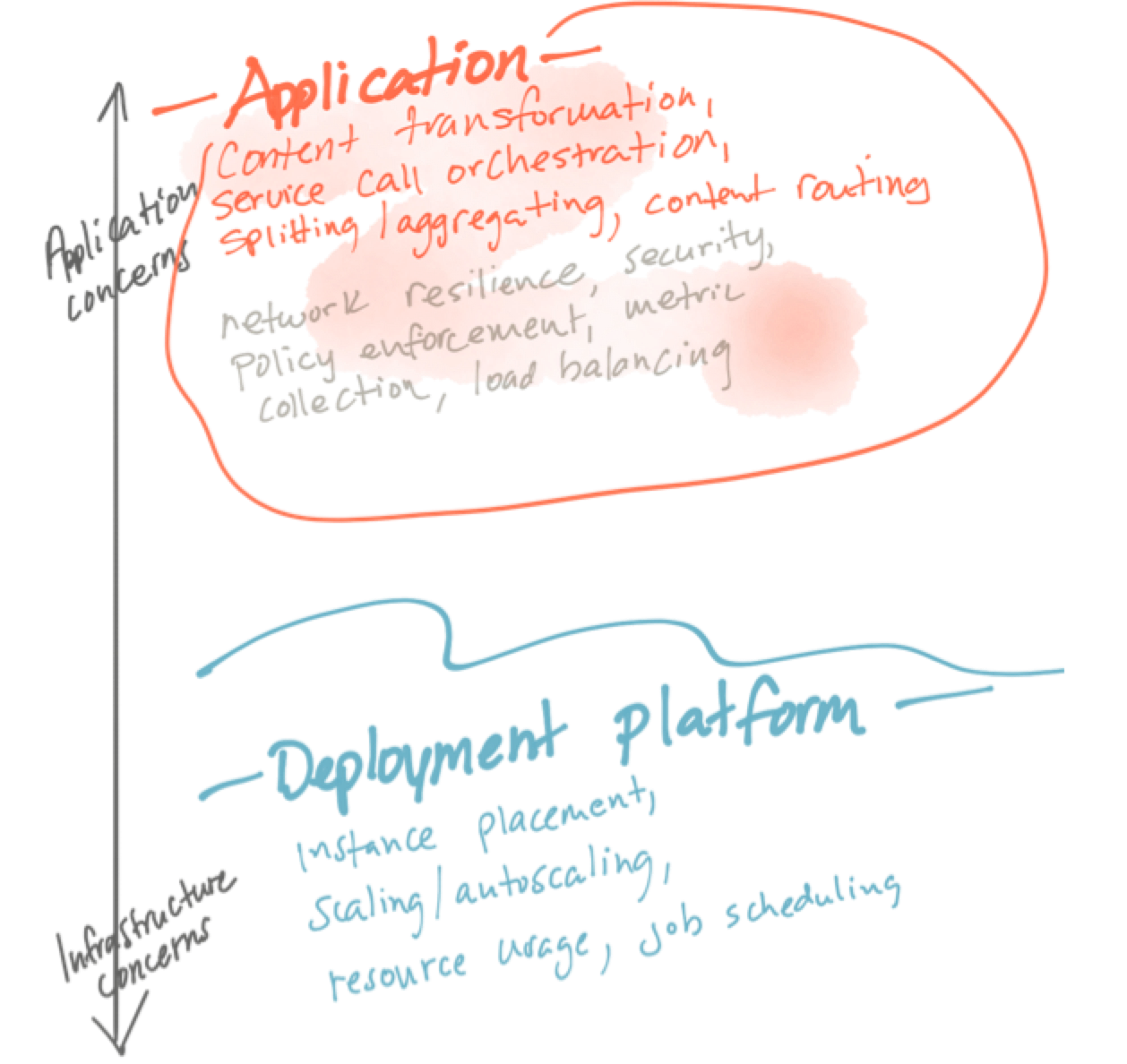
As you know, Netflix OSS libraries around application networking were very Java focused. As organizations started to adopt Netflix OSS and derivatives like spring-cloud-netflix, they met head on with the fact that operationalizing an architecture like that became prohibitive as soon as you started adding other languages. Netflix had the maturity and automation in place to pull it off, other organizations are not Netflix. Some of the problems when trying to operationalize application libraries and frameworks that solve the application-networking spectrum of problems:
- Each language/framework has its own implementation of these concerns
- The implementations won’t be 100% exactly the same; they’ll vary, differ, and sometimes be wrong
- How do you manage, update, patch these libraries? ie, lifecycle management
- These libraries muddy up the logic of the application
- Lots of trust in developers implementing the basics correctly
Istio and service mesh in general aim to solve the application-networking class of problems. Moving the solution to these problems to the service mesh is an optimization for operability. This does not mean it’s not the application’s responsibility anymore, it just means the implementation of these capabilities exist out of process and must be configured.
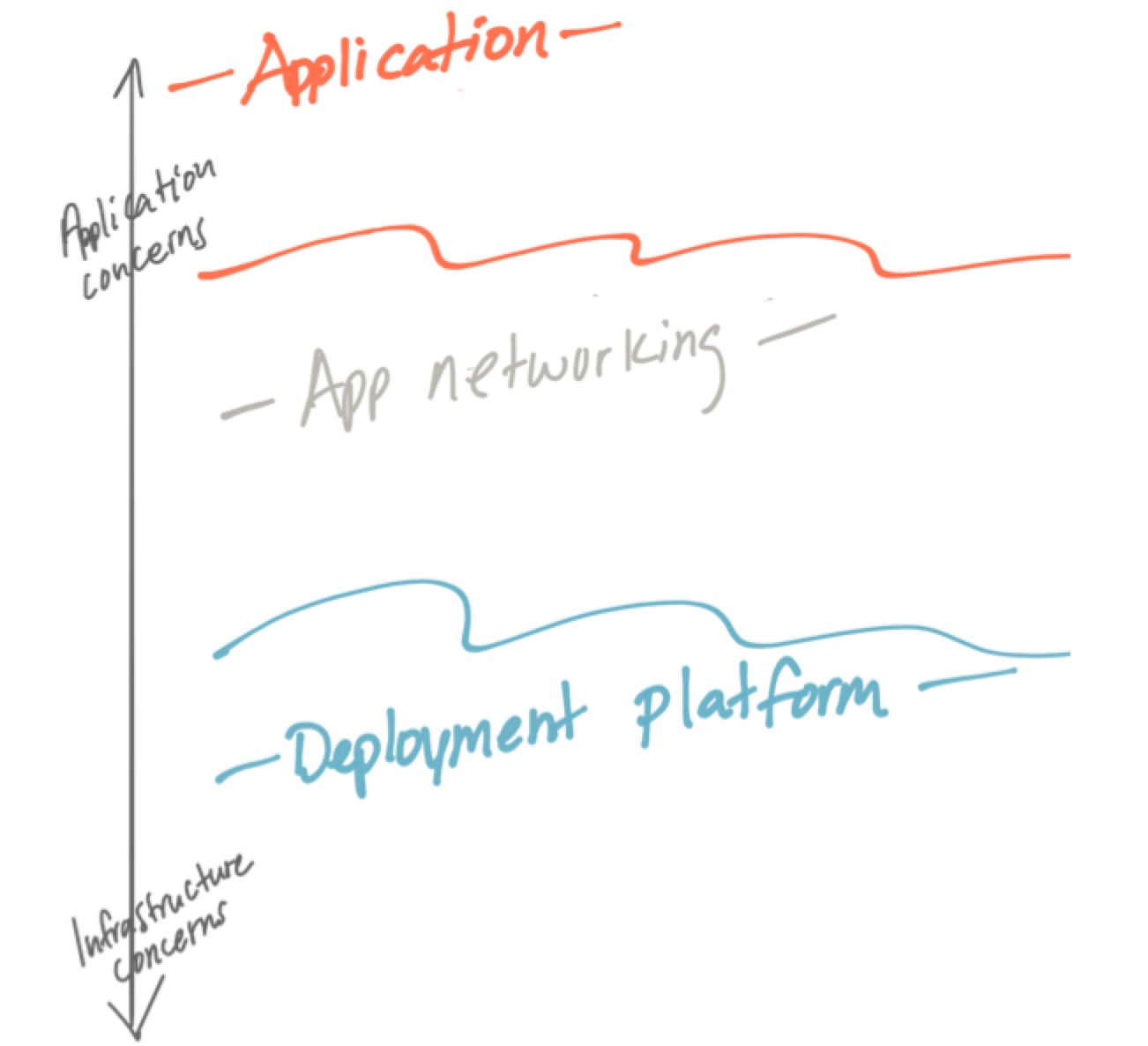
By doing so, we can optimize operability by doing the following:
- One single implementation of these capabilities everywhere
- Consistent functionality
- Correct functionality
- Programmable by both application operators and application developers
Istio and service mesh don’t allow you to offload responsibility to the infrastructure, they just add some level of reliability and optimize for operability. Just like in the end-to-end argument, TCP doesn’t allow you to offload application responsibilities.
Istio helps with application networking class of problems, but what of the application-integration class of probelms? Luckily for developers there’s a myriad of frameworks to help with the application-integration aspects. My favorite for Java developers is Apache Camel which provides a lot of the pieces needed to write correct and safe applications including:
- Call sequencing, multicasting, and orchestration
- []Aggregate responses, transforming message semantics, splitting messages, etc](https://github.com/apache/camel/blob/master/camel-core/src/main/docs/eips/aggregate-eip.adoc)
- Atomicity, consistency issues, saga pattern
- Anti-corruption layers, adapters, boundary transformations
- []Message retries, de-duplication/idempotency](https://github.com/apache/camel/blob/master/camel-core/src/main/docs/eips/idempotentConsumer-eip.adoc)
- Message reordering
- Caching
- Message-level routing
- Retries, timeouts
- Backend/legacy systems integration
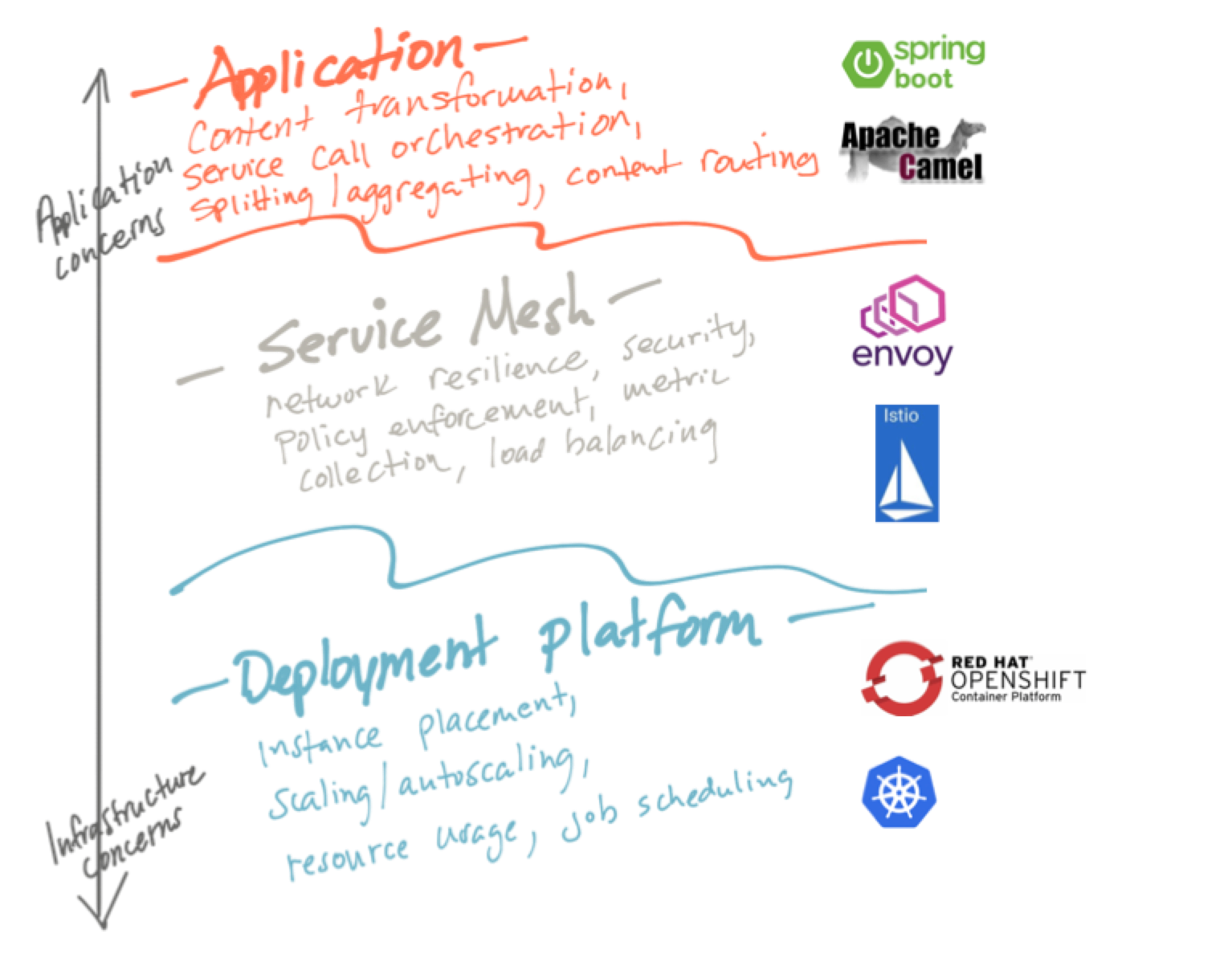
Other frameworks include Spring Integration and even a interesting new programming Language from WSO2 called Ballerina. Mind you, it’s nice to reuse existing patterns and constructs, especially if they exist and are mature for your language of choice, but none of these patterns require you to use a framework.
What about smart endpoints dumb pipes
So with respect to microservices, a friend of mine posed a question regarding the catchy but simplistic “smart endpoints and dump pipes” phrase regarding microservices and how does “making the infrastructure smarter” affect that premise:

The answer I gave was:
The pipes are still dumb; we’re not coercing application logic about application correctness and safety into the infrastructure by using a service mesh. We’re simply making it more reliable, optimizing for operational aspects, and simplifying what the application has to implement (not be responsible for). Feel free to leave comments or reach out on twitter @christianposta if you disagree or have additional thoughts.
If you’d like to learn more about Istio, checkout http://istio.io or the book I wrote about Istio